root@raspberrypi:~# apt-get install omd-1.00



Kurz vor Ende des Jahres sind die Vortragsvideos der OSMC 2016 online verfügbar. Auch dieses Jahr war ich wieder Referent, diesmal mit einem Überblick über die letzten Entwicklungen von OMD, einige Umgebungen, in denen es eingesetzt wird und dem Ausblick auf das, was nach 2016 in die Distribution einfließen könnte.
Dauer des Videos: 60min.
OMD, die Open Monitoring Distribution, bildet heute in vielen Unternehmen das Rückgrat bei der Überwachung unterschiedlichster IT-Komponenten und Services. Für Anfänger ist OMD ein umfassendes Starterpaket, für Consultants eine solide Plattform für individuelle Monitoring-Landschaften. Seit dem Gründungsjahr 2010 wurde OMD kontinuierlich verbessert, mit der OMD-Labs-Edition wurden 2015 moderne Elemente wie InfluxDB und Grafana eingeführt. Das Thema Automatisierung wurde mittlerweile mit Ansible und Coshsh ebenso aufgegriffen. Der Wandel der IT-Welt in Richtung cloud-basierter Services und kurzlebigen Containern stellt eine besondere Herausforderung dar. Der Vortrag zeigt, wie OMD sich dieser in Zukunft stellen wird.
| Author: | Gerhard Laußer |
|---|---|
| Tags: | OMD, Nagios, Icinga, OSMC, Prometheus |
| Categories: | monitoring |
Kiel, 24 Grad, 50 Mann an Bord. Bei unerwartet schönstem Sommerwetter wurde in der Kieler Fachhochschule am 7. und 8. September der elfte Workshop der Monitoring-Community veranstaltet. Das ConSol-Monitoringteam trug mit acht Vorträgen zum Gelingen der Veranstaltung bei. Eine kurze Zusammenfassung:
Bereits mit dem erstem Vortrag nach der Begrüßung, “E2E-Monitoring mit Sakuli”, sorgte Simon Meggle für einen würdigen und technisch anspruchsvollen Auftakt der Veranstaltung. Die Möglichkeit, Sakuli in Docker-Containern einzusetzen und End-to-End-Tests somit praktisch beliebig zu parallelisieren, sorgte für viel Gesprächsstoff.
Damit es jeder zu Hause nachmachen kann, führte Simon dann am zweiten Tag die Teilnehmer in einer Live-Demo durch sein Tutorial “Sakuli-Tests im Docker-Container”.
| Author: | Matthias Gallinger |
|---|---|
| Tags: | Sakuli, Thruk, OMD, Nagios, Icinga, coshsh, Ansible, Kubernetes |
| Categories: | monitoring |
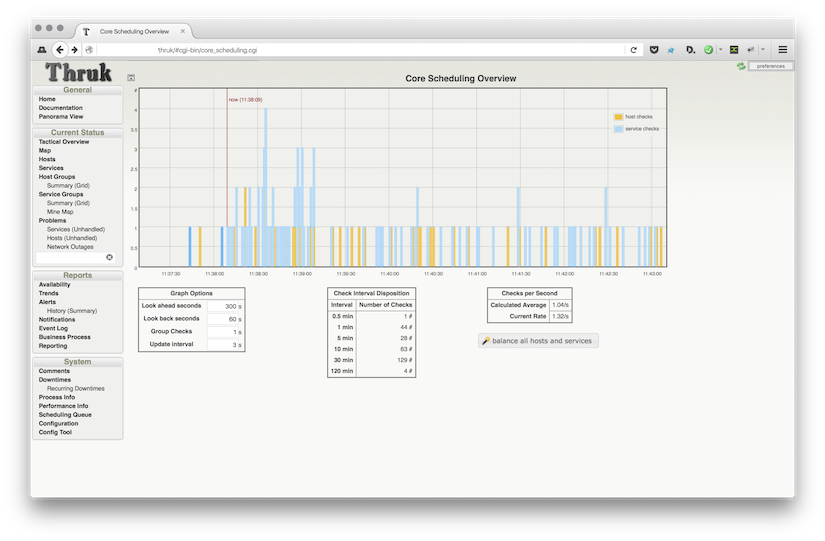
The host- and servicecheck scheduling of Nagios has always been some kind of black box. Checks pile up when using timeperiods which often leads to performance issues while the Nagios host idles again just a minute later. Latest Thruk release (2.06) ships a new addon which visualizes and alleviates this issue.
In der OMD Labs Edition gibt es seit kurzem die Möglichkeit, die Performance-Daten in einer InfluxDB zu speichern. Die Daten werden dabei von der Komponente Nagflux in die InfluxDB geschrieben, Histou übernimmt das Erzeugen der Graphen auf Basis von Templates und Grafana übernimmt die eigentliche Anzeige.
Einen ausführlichen Vortrag vom Autor von Nagflux und Histou, Philip Griesbacher, wird es auf der diesjährigen OSMC geben.
Das Aktivieren des kompletten Gespanns ist ab der Version omd-2.01.20151021-labs-edition aus unserem Testing-Repository in einer OMD site sehr einfach möglich. Erfahrene OMD-Benutzer verwenden die folgenden Kommandos, für OMD-Einsteiger gibt es die ausführlichere bebilderte Anleitung weiter unten.
<br />
omd config set PNP4NAGIOS off<br />
omd config set GRAFANA on<br />
omd config set INFLUXDB on<br />
omd config set NAGFLUX on<br />Beim Monitoring von Netzwerkinterfaces ist es üblich, daß man vier Services konfiguriert. Jeweils einen für Status (up/down), Bandbreite, Errors und Discards. Gelegentlich gab es auch die Anforderung, das alles in einen einzigen Service zu packen, in dem Fall half dann check_multi. Zwar wurde jeweils auch die Konfigurationsdatei für check_multi mit coshsh generiert, aber je simpler, desto besser, daher habe ich einen neuen Modus interface-health eingeführt, so daß check_nwc_health diese vier Checks selber bündelt.
<br />
$ check_nwc_health –hostname 10.37.6.2 –community kaas \<br />
–mode interface-health –name FastEthernet0/0<br />
OK - FastEthernet0/0 is up/up, interface FastEthernet0/0 usage is in:0.01% (12041.88Bits/s) out:0.00% (1435.76Bits/s), interface FastEthernet0/0 errors in:0.00/s out:0.00/s , interface FastEthernet0/0 discards in:0.00/s out:0.00/s | ‘FastEthernet0/0_usage_in’=0.01%;80;90;0;100 ‘FastEthernet0/0_usage_out’=0.00%;80;90;0;100 ‘FastEthernet0/0_traffic_in’=12041.88;80000000;90000000;0;100000000 ‘FastEthernet0/0_traffic_out’=1435.76;80000000;90000000;0;100000000 ‘FastEthernet0/0_errors_in’=0;1;10;; ‘FastEthernet0/0_errors_out’=0;1;10;; ‘FastEthernet0/0_discards_in’=0;1;10;; ‘FastEthernet0/0_discards_out’=0;1;10;;<br />Das Plugin check_nwc_health erfreut sich größter Beliebtheit beim Monitoring von Komponenten in den Core-, Access- und Distribution-Layern, oder kurz: den Netzwerkkomponenten innerhalb von Gebäuden und Standorten.
Das WAN-Monitoring geht aber weit über die üblichen Hardware/CPU/Memory/Interfaces-Checks hinaus.
Für einen OMD-Kunden wurde das Plugin so erweitert, daß er sein europaumspannendes Netzwerk, bestehend aus mehreren tausend WAN-Knoten, umfassend überwachen kann. Den Vergleich mit schweineteuren proprietären Lösungen braucht das Gespann OMD/check_nwc_health seitdem nicht mehr zu fürchten.
Es gibt wieder mal ein neues Plugin, diesmal geht es um die Überwachung von Postfächern/Mailservern/Mailempfang etc. Mit [check_mailbox_health][1] prüft man,
Mit check_mailbox_health lassen sich so auch nicht ganz triviale, auf Mail basierende Geschäftsvorgänge monitoren.
Today [Thruk][1] has released version 2.00 wich is a great milestone and a huge step forward. Instead of adding lots of things, we tried to remove unnecessary dependencies. Version 2.00 comes without the Catalyst framework and many performance improvements, especcially on larger setups.
Beim Monitoring von SAP mit check_sap_health wurden bisher die Bereiche CCMS, Verbuchungssystem und Shortdumps abgedeckt. Mit der neuen Version können nun auch Hintergrundjobs überwacht werden. Folgende Anforderungen wurden implementiert:
One of the most often requested features is the possibility to place hosts, services and host/servicegroups on a geomap.
Now with release 1.88 Thruk made a major change in its panorama dashboard to support this kind of map too.
Wem meine Folien zum Thema Netzwerkmonitoring mit check_nwc_health zu trocken sind kann sich meinen Vortrag auch als Video anschauen. Film ab!
Vorgestern habe ich auf der diesjährigen Open-Source-Monitoring-Konferenz in Nürnberg einen Vortrag über check_nwc_health gehalten.
Hier sind die Folien für diejenigen, die das Pech hatten, nicht dabei zu sein (damit meine ich die Konferenz an sich, nicht meinen Vortrag)
Monitoring von SAP mit den bisher vorhandenen Plugins beschränkte sich auf die Abfrage von CCMS-Metriken. In einem SAP-System steckt aber noch viel mehr, das sich überwachen lässt. Check_sap_health ist ein neues Plugin, welches in Perl geschrieben wurde. Es entstand in einem Projekt, bei dem von unterschiedlichen Standorten aus die Laufzeiten von BAPI-Aufrufen gemessen werden sollten. Durch die einfache Erweiterung des Plugins um selbstgeschriebene Perl-Elemente lassen sich beliebige Funktionen per RFC aufrufen und somit firmenspezifische Logik implementieren.

Der Verlag Packt Publishing ist an mich herangetreten und hat mich gebeten, eine Rezension zum soeben erschienenen Buch Icinga Network Monitoring von Viranch Mehta zu schreiben.
Eigentlich hatte ich keine Zeit, aber wenn mir jemand mit „Keeping in mind your knowledge in this subject and having looked at your contributions, I feel you'd make an excellent reviewer of this book.“ kommt, dann werde ich natürlich schwach.
Das Buch richtet sich an eine Leserschaft, die bisher keinen Kontakt zur Icinga (bzw. Nagios, Naemon oder Shinken) hatte. Linux-Kenntnisse werden aber dennoch vorausgesetzt. Ziel des Autors war es, eine nachvollziehbare (im Sinne von: sofort am Rechner umsetzbar) und möglichst vollständige Anleitung zu erstellen, anhand derer ein Icinga-Neuling (mit ein bisschen Hirnschmalz sind die Schritte aber auch auf die o.g. Geschwister von Icinga anwendbar) in kurzer Zeit ein Basis-Monitoring für seine IT-Landschaft aufsetzen kann.
Lange hat’s gedauert, aber seit heute kann man sich das Debian-Paket für OMD-1.00 vom ConSol-Labs-Repository herunterladen.
root@raspberrypi:~# apt-get install omd-1.00
Die Maschinen unserer Kunden, auf denen wir uns tagtäglich bewegen und Monitoring-Systeme betreiben, haben üblicherweise CPUs und Gigabytes im zweistelligen Bereich. Da wird es schon zur Geduldsprobe, wenn ein Build auf dem Raspberry Pi den halben Tag braucht. Ein ARM11 ist eben kein Xeon und SD ist nicht SSD.
 The developer team of OMD (Open Monitoring Distribution) released the version 1.00 today. Three years after the project started we decided it was time to show that OMD is no longer under development but is a mature, proven product.
The developer team of OMD (Open Monitoring Distribution) released the version 1.00 today. Three years after the project started we decided it was time to show that OMD is no longer under development but is a mature, proven product.
This version contains lots of updated packages including Nagios 3.5.0, Shinken 1.4, Multisite 1.2.2p2, Thruk 1.72, PNP4Nagios 0.6.21, NagVis 1.7.1, check_mk 1.2.2p2 and many more.
Using the OMD Repository installation is as simple as a apt-get install omd. If you have an rpm-based system, it's as simple as yum install omd or zypper install omd.
For those who weren't using OMD yet, now there is no more reason to hesitate.
 Im Februar bestellt und in der letzten Mai-Woche eingetroffen. Die intelligenten Steckdosen von AVM scheinen heiss begehrt zu sein. Jedenfalls kann ich jetzt über meine FRITZ!BOX aufzeichnen, wieviel Strom gewisse Geräte momentan oder aber über einen langen Zeitraum verbrauchen.
Im Februar bestellt und in der letzten Mai-Woche eingetroffen. Die intelligenten Steckdosen von AVM scheinen heiss begehrt zu sein. Jedenfalls kann ich jetzt über meine FRITZ!BOX aufzeichnen, wieviel Strom gewisse Geräte momentan oder aber über einen langen Zeitraum verbrauchen.
Von Berufs wegen juckt's mich natürlich jedesmal in den Fingern, wenn irgendwo Messwerte anfallen. Mein Plugin check_nwc_health kann ja bereits CPU, Speicher und Interfaces einer FRITZ!BOX 7390 abfragen, also war klar, daß die Überwachung der FRITZ!DECT 200 bzw. des gemessenen Energieverbrauchs unbedingt dazugehört.
Die fünfte Ausgabe der ConSol Monitoring Minutes, die sich mit diesem Thema befasst, ist heute ebenfalls entstanden.
 Wie in der dritten Folge schon angekündigt, habe ich zum Thema HSRP ein eigenes Filmchen erstellt. Hier ist die vierte Folge der ConSol Monitoring Minutes, in der gezeigt wird, wie eine mit dem HSRP-Protokoll redundant gemachte Gruppe von Cisco-Routern mit check_nwc_health überwacht wird.
Wie in der dritten Folge schon angekündigt, habe ich zum Thema HSRP ein eigenes Filmchen erstellt. Hier ist die vierte Folge der ConSol Monitoring Minutes, in der gezeigt wird, wie eine mit dem HSRP-Protokoll redundant gemachte Gruppe von Cisco-Routern mit check_nwc_health überwacht wird.
Cisco WLC dienen dazu, Access Points zu verwalten und an ein Backbone-Netz anzubinden. Es gibt zwar schon ein paar Plugins, um diese Geräte mit Nagios zu überwachen, aber ich mag es nicht, für jeden Service ein eigenes Plugin installieren zu müssen. Daher hat das Schweizer Taschenmesser check_nwc_health jetzt eine weitere Klinge bekommen.
Consulting im Bereich Monitoring wird nie langweilig. Ständig wird man mit neuen Anforderungen konfrontiert, so wie vergangene Woche:
Blue Coat ProxyNG Appliances sollten überwacht werden, genauer gesagt das Modell SG600. Diese Appliances finden Verwendung in Application Delivery Networks (ADN), wo sie für die performante Auslieferung von Geschäftsanwendungen und Schutz vor web-basierten Bedrohungen sorgen.
Und jetzt zum Monitoring…
Anlässlich der neuen Videoserie "ConSol Monitoring Minutes" habe ich mir überlegt, wie man die Zahl der Zugriffe auf ein YouTube-Video mit einem Nagios-Plugin auslesen und mit PNP4Nagios aufzeichnen kann. Ein eigenes Plugin müsste dazu die Informationen herunterladen, Kennzahlen aus dem Resultat herausparsen, ausgeben und nicht zuletzt irgendwie auf Download-Fehler reagieren. Mit check_logfiles, einer kleinen Konfigurationsdatei und der YouTube-API ist das aber kein Problem.
| Author: | Gerhard Laußer |
|---|---|
| Tags: | check_logfiles, heino, Icinga, Nagios, Shinken, youtube |
| Categories: | monitoring minutes, nagios, shinken |
Keeping an eye on cpu usage of your servers is one of the basic things in system monitoring. For Nagios (and Shinken, of course) you’ll find plenty of plugins for this task. However, i was never happy with the way they work. Most of the plugins you can download work like this: read a counter - sleep - re-read the counter. This technique not only adds an extra delay to the execution time of the plugin, but it only shows the state of things within a small time frame. If you run such a plugin every 5 minutes and it sleeps 5 seconds between the two measurements, you don’t know what happens in the other 295 seconds. This is a very small sample rate.
Wer sich die neueste Version von Icinga zum Ausprobieren herunterladen will, greift aus Bequemlichkeit sicher auf die virtuelle Maschine zurück, die bereits eine vorgefertigte, vollständige Installation enthält. Das dabei verwendete ova-Format kann allerdings nicht ohne weiteres in einer VMware-Umgebung verwendet werden. Zwar taucht auch ova in den von VMware unterstützten Virtualisierungsformaten auf, in diesem speziellen Fall trifft das jedoch nicht zu. Der VMware vCenter Converter zumindest weigert sich, die Icinga-Datei anzunehmen. Was man tun muss, um Icinga.ova in einen ESX-Server hochzuladen, wird hier beschrieben.