


Before we go into the details in the following parts, this page gives an
overview of current Big Data solutions and shows how caches fit in as one
approach to tackle the Big Data challenge.
As the exponentially decreasing costs of data storage have made the cost of
recording and storing data almost free, data growth has become one
of the biggest challenges faced by today’s organizations.
The term Big Data was coined to
describe a collection of data sets so large and complex that it becomes
difficult to handle using traditional, centralized solutions.
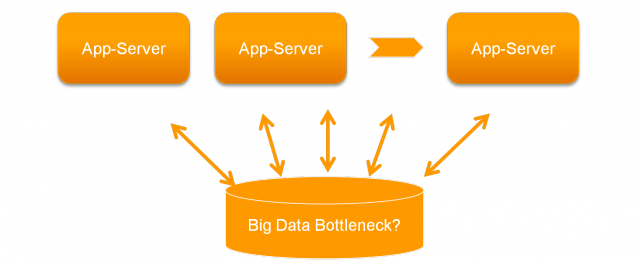
Modern Java application servers support clustered deployments, and provide
good horizontal scalability for growing applications. However, traditional
centralized shared data stores often become the major performance bottleneck
when the amount of data grows.
The following is an overview of current approaches in Big Data solutions.
Overview: The Hadoop File System (HDFS),
which is originally based on the
Google File System (GFS)
is one of the most established technologies in Big Data.
The basic idea is that, instead of making servers larger and larger,
data should be distributed among multiple commodity hardware servers.
Apart from the scalable data storage, Hadoop also provides an infrastructure
for processing data: Map/Reduce Jobs
can be distributed among the servers, such that each server processes the
part of the data that is locally available.
Overview: While file systems are just a flat store for unstructured data,
NoSQL databases allow for relational structuring of the data. In most cases,
NoSQL does not aim at providing the full relational capabilities of SQL
databases, but it provides simpler relations, like the Key/Value relation
in Hash tables.
Among common implementations are HBase, which
is based on Hadoop, and MongoDB.
Although the solutions above have very different roots, the differences
between them begin to blur. There are caches supporting distributed
Lucene indexes and Map/Reduce Jobs, there are combinations of distributed
file systems with Lucene clusters on top, etc.
On this page, we gave a very brief overview of related work.
We pointed out that Caches are used to implement In-Memory Data Management
Systems, which are one among other Big Data solutions. The specific strengths
of In-Memory Data Management Systems are very fast read and write operations.
In the next part, we will introduce the example application.