


AWS Cloud Development Kit (CDK) is a relatively new kid on the block. It is a tool for defining Infrastructure as Code (IaC) and is considered to be the future successor of AWS CloudFormation.
This article overviews the IaC approach, introduces a reader to the AWS CDK, shows what problems it aims to solve and presents a simple example application implemented with it.
Infrastructure as Code AWS whitepaper describes IaC the following way:
Rather than relying on manually performed steps, both administrators and developers can instantiate infrastructure using configuration files. Infrastructure as Code treats these configuration files as software code. These files can be used to produce a set of artifacts, namely the compute, storage, network, and application services that comprise an operating environment. Infrastructure as Code eliminates configuration drift through automation, thereby increasing the speed and agility of infrastructure deployments.
So the idea is that you describe your VPC configuration, RDS instances, S3 buckets, API gateway endpoints and other AWS resources in text files, store them in git and then use a tool which reads them and provisiones the corresponding cloud resources (i.e. the infrastructure) for you:
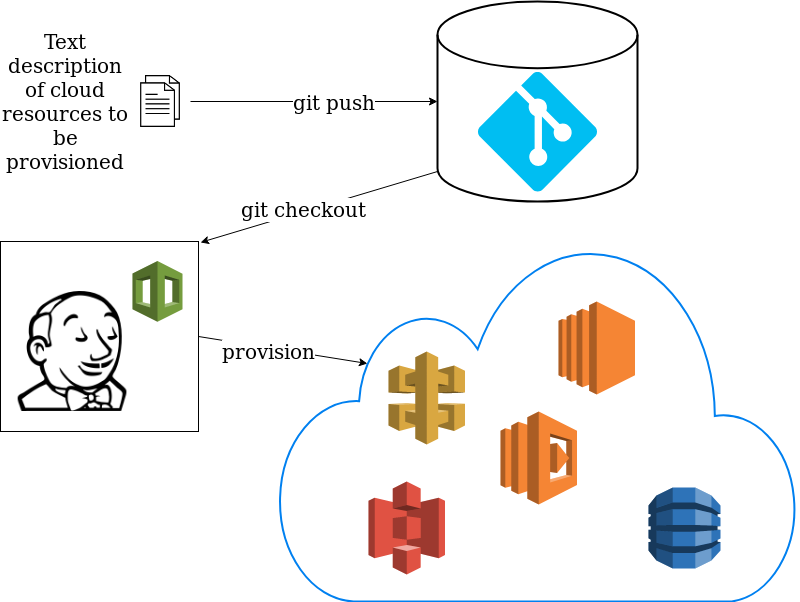
Since the infrastructure configuration files are stored in a git repository they are treated essentially as code (which may be stored in the same repository) and hence the name – Infrastructure as Code (IaC).
This IaC approach gives you the following advantages:
* git gives you versioning out of the box. You can e.g. tag commits according to some versioning scheme such as semantic versioning.
* If you already use Gitflow on your project, you can apply it to your infrastructure as well because it “lives” now in a repository. And, in general, all your git-related skills, processes and operations can be “reused” i.e. you can review / merge / tag / revert / cherry-pick your infrastructure.
* Human errors are minimized. Since your infrastructure is created automatically by a tool, the risk of making a typo is much lower.
* Faster development iterations can be achieved because you do not need to create your infrastructure manually but rather it is created automatically for you. Saved time can be invested in development and other important job.
I’ll try to draw analogy between development of IaC approaches and time periods of human history in a humorous way.

In the Early Middle Ages people used to rely on bash scripting heavily. Developers would script AWS CLI commands, commit them to git and then let a Jenkins pipeline run them.
This old technique has all the key characteristics of an IaC approach:
* Provisioning of an infrastructure is automated.
* The bash scripts are stored in git and hence the infrastructure is treated as code.
* The scripts are versioned by git and thus the infrastructure is also versioned.
Aside from the Great Plague, poor hygiene and permanent wars, back in those dismal days there were also the following problems:
* Ugly echo-based debugging sessions with bash scripts.
* Inability to run bash scripts locally if you happened to have Windows.
* Constant googling “How to implement X in bash?” and applying trial and error approach to writing bash scripts.
* Difficulties with supporting and developing large code bases of interdependent bash scripts.
* Weak or no code completion and inspection support in your IDE.

A little later, in the Late Middle Ages the idea of using the boto3 started to spread in masses. boto3 is a Python library which provides API to AWS cloud services. At that time people used to write Python scripts which gave advantages over bash scripting such as:
* Better IDE support. It was still not perfect because Python is dynamically typed.
* Better cross-platformness thanks to Python’s ability to run on all major OSes.
* Less shooting oneself in the foot because of bash gotchas.
Things got a little bit better. However it was still a scripting-based imperative IaC solution but this time with Python instead of bash.

And then the Industrial Age came with the invention of the steam engine CloudFormation. CloudFormation was and currently still is the “official” answer to the question “How do I do IaC in AWS?” (we’ll get to that later).
Some of the great advantages of CloudFormation are:
* CloudFormation introduced the concept of stacks which are basically bundles of AWS resources. These bundled resources can be deleted all at once by deleting the corresponding stack.
* CloudFormation checks whether you’ve set all the necessary properties to the AWS resources and if something is missing no resources will be provisioned. Back in the Late Middle Ages you would have an exception in the middle of a script and your infrastructure would have been provisioned only partially i.e. it would have been in an inconsistent state.
* CloudFormation is declarative. You describe the end result and CloudFormation applies the steps necessary to reach it. You don’t need to write create and wait commands as it was the case with the scripting, but rather you can concentrate on architecting activities.

In 2018 during its yearly re:Invent conference AWS introduced the AWS CDK which should lead us hopefully to the bright cloud future. CDK combines the best of both worlds. It is declarative like CloudFormation and yet you can use full power of your favorite programming language and work in your favorite IDE.
AWS CDK is a CLI tool and a set of libraries. The CDK libraries let you define your AWS infrastructure by writing code in one of five supported programming languages: Typescript, Javascript, Java, Python and C#. The CDK CLI tool generates then CloudFormation templates from the code you’ve written and provisiones the infrastructure.
Although you do write code to define your infrastructure, it is still defined in a declarative manner because this code is different from the scripting that we used to have in the Middle Ages. You don’t write instructions like “create a S3 bucket” and “poll and wait until S3 bucket is fully provisioned” but rather you write instructions like “add S3 bucket to my infrastructure with properties X, Y and Z”.
There are three main concepts in CDK:
* application
* stack
* construct
An application comprises all the cloud resources that you are going to provision in AWS. It represents basically all your workloads that you are going to deploy to AWS in order to solve the particular business problem you have (or your customer has). An application could consist e.g. of a VPC, RDS instances running databases, EC2 instances running your application and web servers and ALBs distributing load over the EC2 instances.
The application consists of stacks which correspond to CloudFormation stacks. Stacks are there to logically bundle resources which should be deployed together as one unit. You could have e.g. stack A for VPC, Subnets, Security Groups, Network ACLs, Route Tables and other VPC-related configuration, stack B for RDS instances, stack C for application servers and their ALBs and stack D for web servers and their ALBs.
Each stack can include AWS resources either directly or as constructs. A construct is a set of AWS resources which represents a reusable component which may be included in multiple other CDK applications. Dynamo table viewer is an example of a construct.
OK, so you start writing a CDK application. You add a couple of stacks to it. The stacks consist of various AWS resources such as SQS queues, Lambdas, S3 buckets, DynamoDB tables etc. You add those resources using the corresponding CDK libraries such as @aws-cdk/aws-ec2. And then you use the CDK tool to deploy your application. The tool executes your code, finds the stacks, generates a CloudFormation template for each of them and deploys these templates producing a CloudFormation stack for each of them:
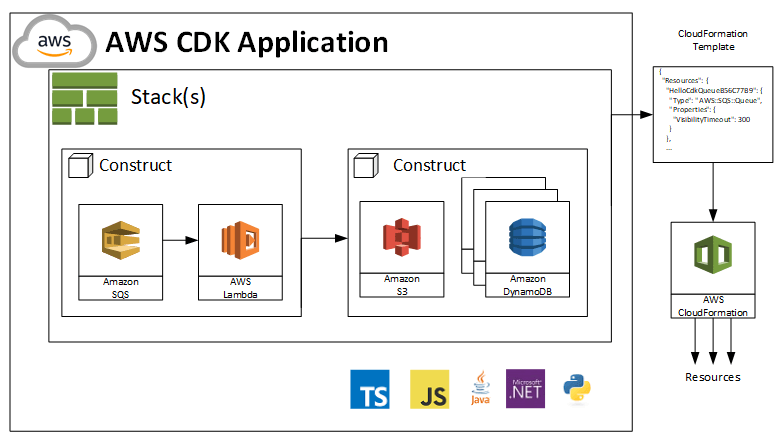
And that’s it. Your app is in the cloud. That’s how CDK works on a high level.
AWS CDK is open source and is written primarily in Typescript. Libraries for the rest of the languages are generated together with bindings (except for Javascript) which delegate execution to Node.js engine as described in the CDK developer guide:
The AWS CDK is developed in TypeScript and transpiled to JavaScript. Bindings for the other supported languages make use of the AWS CDK engine running on Node.js, as does the cdk command-line tool.
The main reasons why you might consider CDK for development of AWS-based cloud applications are the following:
* You can use full power of your favorite programming language (if it’s one of the five supported) in which you are proficient while still staying declarative when defining your infrastructure.
* Your favorite IDE supports you with code completion, snippets, smart refactorings and other goodies.
* The CDK app defining your infrastracture is usually much shorter than the generated CloudFormation template which you would have had to write if you wouldn’t have used CDK. This is achieved by leveraging the CDK helper methods such as this one (Table.grantReadWriteData) which generates IAM roles and policies with all the necessary permissions.
CDK has reached a stable version 1.x. However, there are many CDK modules with experimental status such as @aws-cdk/aws-s3-deployment (at the time of writing it has experimental status). So the tool is not yet produciton ready and that’s why I mentioned earlier that the “official” answer to the question “How do I do IaC in AWS?” is still the battle-tested CloudFormation.
However, this should not discourage you from trying out CDK e.g. on pilot or small internal projects. If you’ve stated to use CDK and then you realize that you are unhappy with it, you can do the following:
* let CDK generate CloudFormation YAML templates for you
* commit the generated templates to git
* drop CDK and use CloudFormation for futher development
Since Typescript is the main CDK’s language the demo CDK application described further has been written in it.
The demo app consists of two stacks, one for front-end and another one for back-end:
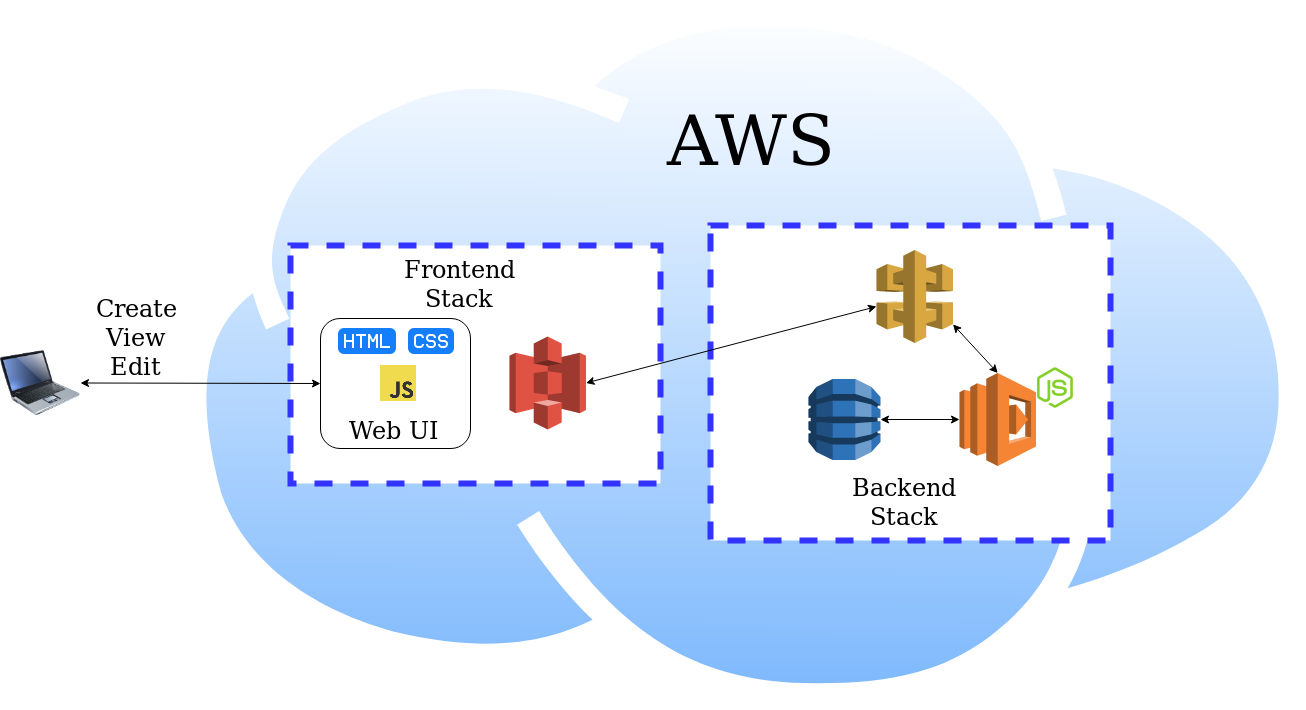
The front-end stack represents a simple HTML / CSS / Javascript application hosted on an S3 bucket. This application consists of three pages for viewing, creating and editing orders. The orders are saved in a DynamoDB Table. Logic is executed by Lambdas which are triggered via the API Gateway.
In order to deploy the app, you need the following:
* Node.js (version 10.3.0+)
* AWS CDK CLI (npm install -g aws-cdk@1.14.0)
* AWS environment variables with AWS access key and some other settings:
export AWS_ACCESS_KEY_ID=AKIAIOSFODNN7EXAMPLE
export AWS_SECRET_ACCESS_KEY=wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
export AWS_DEFAULT_REGION=us-east-1
export AWS_DEFAULT_OUTPUT=json
The application can be deployed the following way:
* git clone https://github.com/ConSol/aws-cdk-and-lambda-workshop.git
* cd aws-cdk-and-lambda-workshop
* npm install
* npm run build
* Let CDK bootstrap an environment for itself:
cdk bootstrap
* After bootstrapping you’ll see that CDK has created a S3 staging bucket:
mmustermann@mustermachine:~/aws-cdk-and-lambda-workshop$ aws s3 ls
2019-11-03 10:34:31 cdktoolkit-stagingbucket-1s73ctmtae8rs
This staging bucket is used e.g. as an intermediate buffer to store a Lambda’s code.
* First deploy the backend stack with:
cdk deploy BackendStack
* Answer y when you see the prompt “Do you wish to deploy these changes?”
* After deployment has finished, you’ll see the URL of the provisioned API Gateway endpoint in the console output:
Outputs:
BackendStack.OrderApiEndpoint315A9F2C = https://gwvft2cty1.execute-api.us-east-1.amazonaws.com/prod/
webui/code.js and edit the ORDERS_ENDPOINT_URL to point to the newly created endpoint:const ORDERS_ENDPOINT_URL = "https://gwvft2cty1.execute-api.us-east-1.amazonaws.com/prod/";
cdk deploy FrontendStacky again when you see the prompt.mmustermann@mustermachine:~/aws-cdk-and-lambda-workshop$ aws s3 ls
2019-11-03 10:34:31 cdktoolkit-stagingbucket-1s73ctmtae8rs
2019-11-03 10:48:54 frontendstack-webui258d87a5-dp03mz7lo8hb
https://frontendstack-webui258d87a5-dp03mz7lo8hb.s3.amazonaws.com/index.html
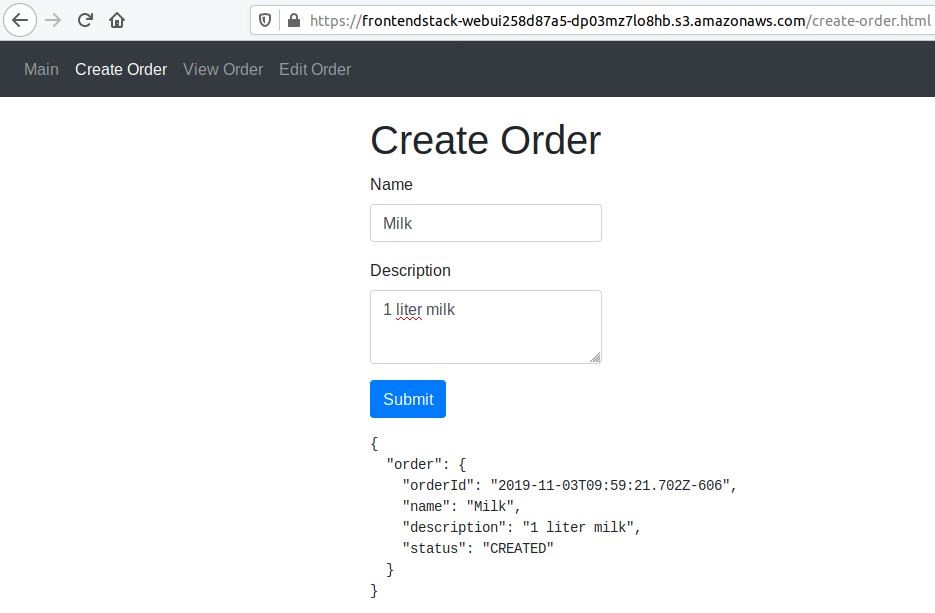
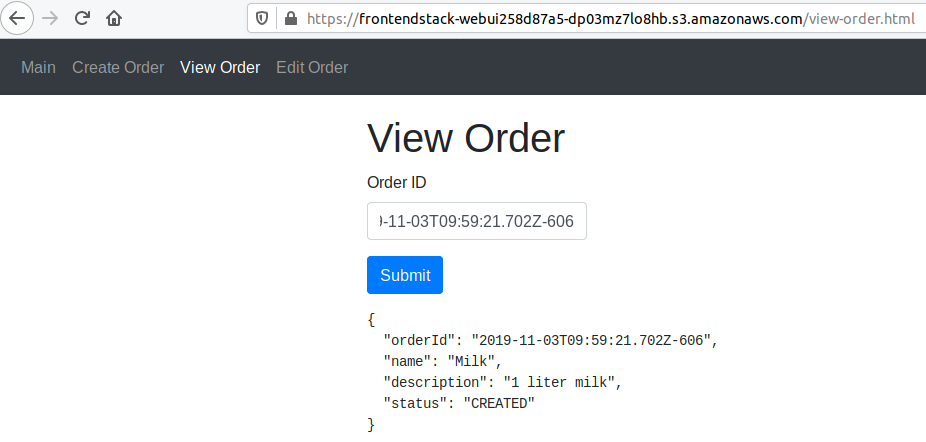
mmustermann@mustermachine:~/aws-cdk-and-lambda-workshop$ aws cloudformation describe-stacks | grep -i stackname
"StackName": "FrontendStack",
"StackName": "BackendStack",
"StackName": "CDKToolkit",
Two stacks have been created to deploy the demo app and the “CDKToolkit” stack has been created by the cdk bootstrap command.
* Let’s copy the contents of the staging S3 bucket and examine them:
mmustermann@mustermachine:~/aws-cdk-and-lambda-workshop$ aws s3 cp --recursive s3://cdktoolkit-stagingbucket-1s73ctmtae8rs cdktoolkit-stagingbucket-1s73ctmtae8rs
mmustermann@mustermachine:~/aws-cdk-and-lambda-workshop$ cd cdktoolkit-stagingbucket-1s73ctmtae8rs/
mmustermann@mustermachine:~/aws-cdk-and-lambda-workshop/cdktoolkit-stagingbucket-1s73ctmtae8rs$ tree .
.
├── assets
│ ├── 5fe8c75cbaa0f422a51f1bca34363659ace9170913b7d4d29389e1612e12651e
│ │ └── e2b9658164b03c078c7e06e5da82a09b297b220e5a8e19229b883a2cf4618077.zip
│ ├── 6416c21be320b522db64c705872c0a54d788e3df57b34a5f0d1e8602d7521430
│ │ └── ecc015fefc60848dbfe64452efab244d7d337e4d0c9d0effabfd9bd0ecffcdf6.zip
│ └── bc86562e57cb99459725e82c8c6a382f9a6a6639ece5d0a056b29400aeaea588
│ └── bf2f3df4eb41f9d92ee603498716dcb8b3e0b82068f7938cbfb60db26c385666.zip
└── cdk
├── BackendStack
│ └── d9956d67a6a21540132f235fc971ca743e145b5c4669c9bd42194e698f6c533b.yml
└── FrontendStack
└── 896e7586f0d351cfcebc19b091df6b84dfd63ad91eb99f4c1f3625e6eafb5db9.yml
7 directories, 5 files
You can see there are 2 CloudFormation YAML templates generated by the CDK from the Typescript code defining the infrastructure (we’ll get to the code later) and 3 ZIP archives. The first one contains the HTML / CSS / Javascript front-end app:
mmustermann@mustermachine:~/aws-cdk-and-lambda-workshop/cdktoolkit-stagingbucket-1s73ctmtae8rs$ zip -v --test assets/5fe8c75cbaa0f422a51f1bca34363659ace9170913b7d4d29389e1612e12651e/e2b9658164b03c078c7e06e5da82a09b297b220e5a8e19229b883a2cf4618077.zip
Archive: assets/5fe8c75cbaa0f422a51f1bca34363659ace9170913b7d4d29389e1612e12651e/e2b9658164b03c078c7e06e5da82a09b297b220e5a8e19229b883a2cf4618077.zip
testing: code.js OK
testing: create-order.html OK
testing: edit-order.html OK
testing: favicon.png OK
testing: index.html OK
testing: styles.css OK
testing: vendor/bootstrap.min.css OK
testing: vendor/bootstrap.min.js OK
testing: vendor/jquery-3.3.1.min.js OK
testing: vendor/popper.min.js OK
testing: view-order.html OK
No errors detected in compressed data of assets/5fe8c75cbaa0f422a51f1bca34363659ace9170913b7d4d29389e1612e12651e/e2b9658164b03c078c7e06e5da82a09b297b220e5a8e19229b883a2cf4618077.zip.
test of assets/5fe8c75cbaa0f422a51f1bca34363659ace9170913b7d4d29389e1612e12651e/e2b9658164b03c078c7e06e5da82a09b297b220e5a8e19229b883a2cf4618077.zip OK
The second one contains Python code for an auxiliary Lambda which copies data between S3 buckets:
mmustermann@mustermachine:~/aws-cdk-and-lambda-workshop/cdktoolkit-stagingbucket-1s73ctmtae8rs$ zip -v --test assets/6416c21be320b522db64c705872c0a54d788e3df57b34a5f0d1e8602d7521430/ecc015fefc60848dbfe64452efab244d7d337e4d0c9d0effabfd9bd0ecffcdf6.zip
Archive: assets/6416c21be320b522db64c705872c0a54d788e3df57b34a5f0d1e8602d7521430/ecc015fefc60848dbfe64452efab244d7d337e4d0c9d0effabfd9bd0ecffcdf6.zip
testing: awscli/ OK
testing: awscli/alias.py OK
testing: awscli/paramfile.py OK
... lots of other Python files ...
testing: rsa/_compat.py OK
testing: rsa/core.py OK
No errors detected in compressed data of assets/6416c21be320b522db64c705872c0a54d788e3df57b34a5f0d1e8602d7521430/ecc015fefc60848dbfe64452efab244d7d337e4d0c9d0effabfd9bd0ecffcdf6.zip.
test of assets/6416c21be320b522db64c705872c0a54d788e3df57b34a5f0d1e8602d7521430/ecc015fefc60848dbfe64452efab244d7d337e4d0c9d0effabfd9bd0ecffcdf6.zip OK
This Lambda comes from the @aws-cdk/aws-s3-deployment CDK library:
> This is what happens under the hood:
> 1. When this stack is deployed (either via cdk deploy or via CI/CD), the contents of the local website-dist directory will be archived and uploaded to an intermediary assets bucket. If there is more than one source, they will be individually uploaded.
> 2. The BucketDeployment construct synthesizes a custom CloudFormation resource of type Custom::CDKBucketDeployment into the template. The source bucket/key is set to point to the assets bucket.
> 3. The custom resource downloads the .zip archive, extracts it and issues aws s3 sync –delete against the destination bucket (in this case websiteBucket). If there is more than one source, the sources will be downloaded and merged pre-deployment at this step.
And the third ZIP contains code of the Lambda which processes orders:
mmustermann@mustermachine:~/aws-cdk-and-lambda-workshop/cdktoolkit-stagingbucket-1s73ctmtae8rs$ zip -v --test assets/bc86562e57cb99459725e82c8c6a382f9a6a6639ece5d0a056b29400aeaea588/bf2f3df4eb41f9d92ee603498716dcb8b3e0b82068f7938cbfb60db26c385666.zip
Archive: assets/bc86562e57cb99459725e82c8c6a382f9a6a6639ece5d0a056b29400aeaea588/bf2f3df4eb41f9d92ee603498716dcb8b3e0b82068f7938cbfb60db26c385666.zip
testing: main.d.ts OK
testing: main.js OK
testing: main.ts OK
No errors detected in compressed data of assets/bc86562e57cb99459725e82c8c6a382f9a6a6639ece5d0a056b29400aeaea588/bf2f3df4eb41f9d92ee603498716dcb8b3e0b82068f7938cbfb60db26c385666.zip.
test of assets/bc86562e57cb99459725e82c8c6a382f9a6a6639ece5d0a056b29400aeaea588/bf2f3df4eb41f9d92ee603498716dcb8b3e0b82068f7938cbfb60db26c385666.zip OK
Now let’s examine the code from which those ZIPs and CloudFormation YAML templates are created.
The project has been generated by the cdk init --language=typescript command. This command has basically created an NPM package. You can recognize that by the package.json and .npmignore files. Since the Typescript has been selected, the tsconfig.json has also been generated. You can read more on how to create a simple CDK project in the official AWS CDK workshop.
When cdk deploy command executes it looks into the bin/app.ts file:
#!/usr/bin/env node
import "source-map-support/register";
import cdk = require("@aws-cdk/core");
import { EchoStack } from "../lib/echo-stack";
import { BackendStack } from "../lib/backend-stack";
import { FrontendStack } from "../lib/frontend-stack";
const app = new cdk.App();
const echoStack = new EchoStack(app, "EchoStack");
const backendStack = new BackendStack(app, "BackendStack");
const frontendStack = new FrontendStack(app, "FrontendStack");
const ownerTag = new cdk.Tag("owner", "Max.Mustermann");
[echoStack, backendStack, frontendStack].forEach(stack => ownerTag.visit(stack));
You can see an instance of a CDK app is created and 3 CDK stacks are added to it. We have used only BackendStack and FrontendStack stacks. The EchoStack contains a simple Lambda behind an API Gateway which returns internal event object (in HTTP response body as JSON) passed to it by the AWS Lambda runtime. The last two lines are there to tag all resources with “owner” tag equal to “Max.Mustermann”.
The BackendStack which has been deployed first with cdk deploy BackendStack is defined in Typescript the following way:
import cdk = require("@aws-cdk/core");
import lambda = require("@aws-cdk/aws-lambda");
import apigw = require("@aws-cdk/aws-apigateway");
import dynamodb = require("@aws-cdk/aws-dynamodb");
export class BackendStack extends cdk.Stack {
constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
const orders = new dynamodb.Table(this, "Orders", {
partitionKey: {
name: "OrderId",
type: dynamodb.AttributeType.STRING
}
});
const orderResourceHandler = new lambda.Function(this, "OrderResourceHandler", {
runtime: lambda.Runtime.NODEJS_10_X,
code: lambda.Code.asset("order-resource-handler"),
handler: "main.handler",
environment: {
TABLE_NAME: orders.tableName
}
});
orders.grantReadWriteData(orderResourceHandler);
new apigw.LambdaRestApi(this, "OrderApi", {
handler: orderResourceHandler
});
}
}
This stack declares a DynamoDB Table, a Lambda function and an API Gateway which calls the function and passes an HTTP request to it. The implementation of the Lambda is located in the order-resource-handler folder. The usage of the helper method orders.grantReadWriteData(orderResourceHandler) is worth noting. Such methods spare a lot of effort compared to conventional CloudFormation templates because they generate all the necessary IAM roles and policies which would have been needed to be written by hand in the case of CloudFormation.
The FrontendStack is defined the following way:
import cdk = require("@aws-cdk/core");
import s3 = require("@aws-cdk/aws-s3");
import s3Deploy = require("@aws-cdk/aws-s3-deployment");
export class FrontendStack extends cdk.Stack {
constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
const bucket = new s3.Bucket(this, "WebUI", {
websiteIndexDocument: "index.html",
publicReadAccess: true
});
new s3Deploy.BucketDeployment(this, "WebUIDeployment", {
sources: [s3Deploy.Source.asset("webui")],
destinationBucket: bucket
});
}
}
It declares an S3 bucket which is going to be used for hosting an HTML / CSS / Javascript app (publicReadAccess: true). The bucket is populated by the files located in the webui folder (sources: [s3Deploy.Source.asset("webui")]).
If you execute cdk synth BackendStack CDK will generate (synthesize) a CloudFormation template for the BackendStack. The generated template has approximately 400 lines of YAML and the original Typescript code has only approximately 30 lines of code i.e. more than 10 times less.
How to clean up created resources:
* destroy front-end stack:
cdk destroy FrontendStack
y to acknowledge that you want to delete stack’s resources.mmustermann@mustermachine:~/aws-cdk-and-lambda-workshop$ aws cloudformation describe-stacks | grep -i stackname
"StackName": "BackendStack",
"StackName": "CDKToolkit",
mmustermann@mustermachine:~/aws-cdk-and-lambda-workshop$ aws s3 ls
2019-11-03 10:34:31 cdktoolkit-stagingbucket-1s73ctmtae8rs
2019-11-03 10:48:54 frontendstack-webui258d87a5-dp03mz7lo8hb
Currently CDK does not delete non-empty resources such as S3 buckets. The bucket can be deleted with AWS CLI though:
mmustermann@mustermachine:~/aws-cdk-and-lambda-workshop$ aws s3 rb --force s3://frontendstack-webui258d87a5-dp03mz7lo8hb
delete: s3://frontendstack-webui258d87a5-dp03mz7lo8hb/code.js
delete: s3://frontendstack-webui258d87a5-dp03mz7lo8hb/favicon.png
delete: s3://frontendstack-webui258d87a5-dp03mz7lo8hb/edit-order.html
delete: s3://frontendstack-webui258d87a5-dp03mz7lo8hb/create-order.html
delete: s3://frontendstack-webui258d87a5-dp03mz7lo8hb/styles.css
delete: s3://frontendstack-webui258d87a5-dp03mz7lo8hb/vendor/bootstrap.min.js
delete: s3://frontendstack-webui258d87a5-dp03mz7lo8hb/index.html
delete: s3://frontendstack-webui258d87a5-dp03mz7lo8hb/vendor/jquery-3.3.1.min.js
delete: s3://frontendstack-webui258d87a5-dp03mz7lo8hb/vendor/popper.min.js
delete: s3://frontendstack-webui258d87a5-dp03mz7lo8hb/vendor/bootstrap.min.css
delete: s3://frontendstack-webui258d87a5-dp03mz7lo8hb/view-order.html
remove_bucket: frontendstack-webui258d87a5-dp03mz7lo8hb
cdk destroy BackendStack command.mmustermann@mustermachine:~/aws-cdk-and-lambda-workshop$ aws dynamodb list-tables
{
"TableNames": [
"BackendStack-OrdersA9B65338-1ULLFMB1DGX6A"
]
}
mmustermann@mustermachine:~/aws-cdk-and-lambda-workshop$ aws dynamodb delete-table --table-name BackendStack-OrdersA9B65338-1ULLFMB1DGX6A
{
"TableDescription": {
"TableName": "BackendStack-OrdersA9B65338-1ULLFMB1DGX6A",
"TableStatus": "DELETING",
"ProvisionedThroughput": {
"NumberOfDecreasesToday": 0,
"ReadCapacityUnits": 5,
"WriteCapacityUnits": 5
},
"TableSizeBytes": 0,
"ItemCount": 0,
"TableArn": "arn:aws:dynamodb:us-east-1:251705002408:table/BackendStack-OrdersA9B65338-1ULLFMB1DGX6A",
"TableId": "5d2f7ed1-6f90-4b42-a8d5-0b6a1a651cc9"
}
}
CDKToolkit CloudFormation stack needs to be deleted. The corresponding S3 bucket has to be also deleted separately:mmustermann@mustermachine:~/aws-cdk-and-lambda-workshop$ aws cloudformation delete-stack --stack-name CDKToolkit
mmustermann@mustermachine:~/aws-cdk-and-lambda-workshop$ aws s3 rb --force s3://cdktoolkit-stagingbucket-1s73ctmtae8rs
delete: s3://cdktoolkit-stagingbucket-1s73ctmtae8rs/cdk/BackendStack/d9956d67a6a21540132f235fc971ca743e145b5c4669c9bd42194e698f6c533b.yml
delete: s3://cdktoolkit-stagingbucket-1s73ctmtae8rs/assets/6416c21be320b522db64c705872c0a54d788e3df57b34a5f0d1e8602d7521430/ecc015fefc60848dbfe64452efab244d7d337e4d0c9d0effabfd9bd0ecffcdf6.zip
delete: s3://cdktoolkit-stagingbucket-1s73ctmtae8rs/cdk/FrontendStack/896e7586f0d351cfcebc19b091df6b84dfd63ad91eb99f4c1f3625e6eafb5db9.yml
delete: s3://cdktoolkit-stagingbucket-1s73ctmtae8rs/assets/bc86562e57cb99459725e82c8c6a382f9a6a6639ece5d0a056b29400aeaea588/bf2f3df4eb41f9d92ee603498716dcb8b3e0b82068f7938cbfb60db26c385666.zip
delete: s3://cdktoolkit-stagingbucket-1s73ctmtae8rs/assets/5fe8c75cbaa0f422a51f1bca34363659ace9170913b7d4d29389e1612e12651e/e2b9658164b03c078c7e06e5da82a09b297b220e5a8e19229b883a2cf4618077.zip
remove_bucket: cdktoolkit-stagingbucket-1s73ctmtae8rs
AWS CDK will probably supersede CloudFormation in the next 10-15 years. The tool combines best features of CloudFormation (declarativeness) and scripting (expressive power of modern programming languages).
Currently CDK leans on CloudFormation by generating CloudFormation templates. However, AWS develops together with CDK the Cloud Assembly specification which basically defines a ZIP archive containing artifacts deployable to a cloud. Cloud Assembly’s ZIP archive is very similar to a WAR. The latter is deployed to a Java application server and the former is deployed to a cloud. It looks that the Cloud Assembly mechanism will become default for the CDK tool.
CDK is AWS-only IaC tool. There is also the Pulumi which is a rival multi-cloud-capable solution. It’ll be exciting to see how these modern IaC tools gain more developers mindshare.