


The host- and servicecheck scheduling of Nagios has always been some kind of black box. Checks pile up when using timeperiods which often leads to performance issues while the Nagios host idles again just a minute later. Latest Thruk release (2.06) ships a new addon which visualizes and alleviates this issue.
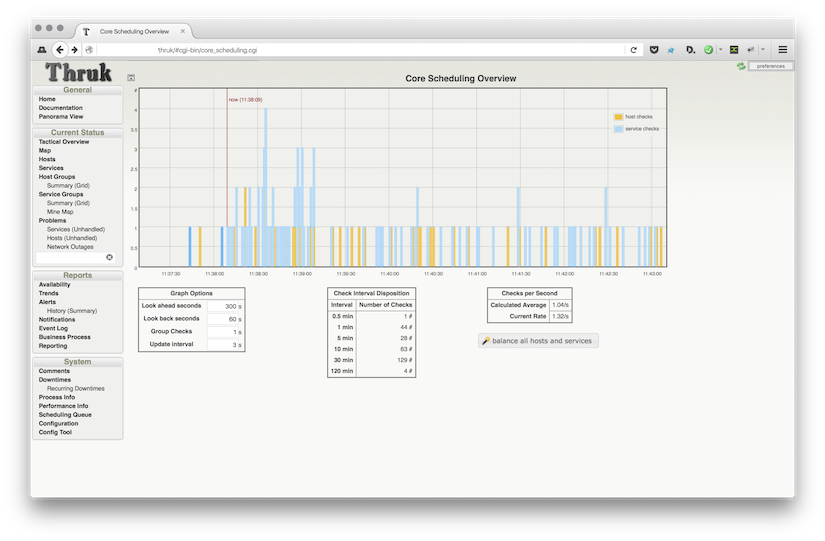
The first step in fixing a problem is visualizing the problem. Therefor the ‘Core Scheduling Plugin’ from the latest Thruk release draws a chart with all scheduled active host and service checks.
The red line draws the current time, so everything right from that line are scheduled checks while everything left from that line should be actually running checks. Running checks have a darker colored bar in this chart, so if there are checks behind the current date which are not yet running, we have some latency.
You also should see immediatly if you have lots of long running checks which also might cause performance problems, because long running plugins use memory and cpu for a longer time.
Fixing those piles of checks is easy. Just press the balance all checks button and Thruk will send force reschedule commands in order to balance out all active checks.
Sometimes you don’t want to reschedule all services, which can be quite a number if larger installations. If often helps to balance only specific servicegroups or heavy checks. In order to do this, you can use the filter options from the top left and only select a subset of checks.
If you want to do this automatically, for example from cron, you could use the thruk cli tool.
Reschedule everything:
%> thruk -a fix_scheduling
Reschedule hostgroup test:
%> thruk -a fix_scheduling=hg:test
Reschedule servicegroup test:
%> thruk -a fix_scheduling=sg:test