


Caches are a standard technique for increasing performance when transferring
data. Caches are widely deployed in both, hardware (CPU, disks, etc), and
software.
Our series on software caches in Java application servers
will introduce current implementations
(Ehcache, Hazelcast,
Infinispan),
and to point out their specific strengths and weaknesses.
Before we start examining the specific implementations, we finish our introduction
with an overview and categorization of related work and Big Data solutions:
The remainder of our series is structured as follows:
Part 01 introduces an example application,
using the Cache as a stand-alone, temporary data store for user events.
The example application is introduced together with a ConcurrentMap-based reference
implementation, and will subsequently be refactored to using Caches in the following parts.
There are a lot of more advanced applications for caches in Java server environments,
some of them are listed in JSR 107:
Our starting point is a simple, stand-alone example for an handmade cache used for logging
user based events:
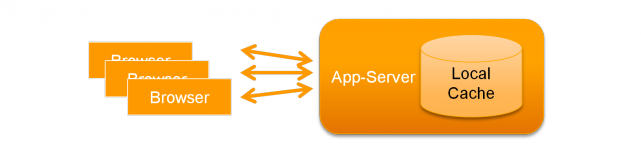
Part 02 shows the basic implementation of local caches,
as defined in JSR 107.
Subsequently, the example application is implemented using the three
respective caches: Ehcache,
Hazelcast, and
Infinispan.
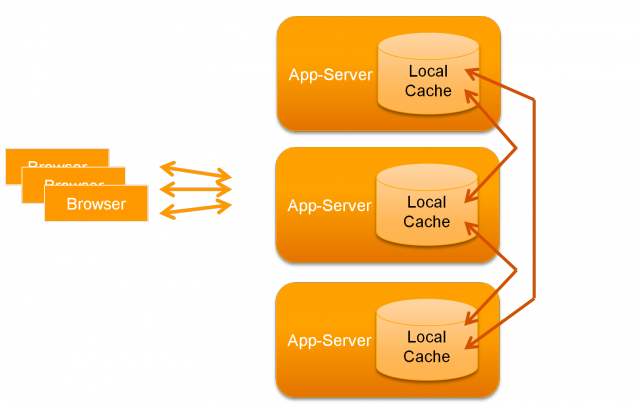
Part 03 introduces
peer-to-peer clustering as a way to share a
virtual cache among multiple application server
instances.
As it turns out, there are fundamental differences in the way peer-to-peer
clustering is implemented in Ehcache,
Hazelcast, and
Infinispan.
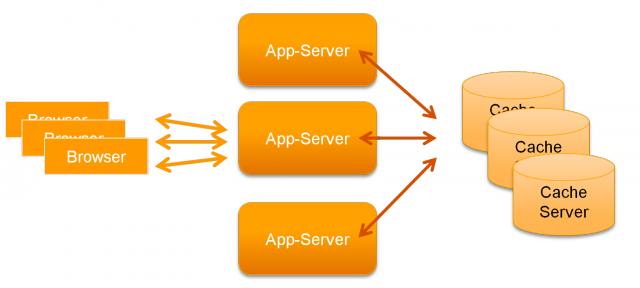
Part 04 shows how a stand-alone cache
cluster can be implemented. The implementation is reviewed for
Ehcache,
Hazelcast, and
Infinispan.
Our series concludes with an overview of some advanced topics,
like deployments as a second level database cache, or a non-standard feature
comparison matrix.
The next page gives an overview of related work and Big Data solutions: