


AWS offers a great service called “Amazon Elastic Container Service for Kubernetes” (AWS EKS).
The setup guide can be found here: Offical AWS EKS getting started guide
If you overload such a cluster it easily happens that your Kubelet gets “Out of Memory” (OOM) errors and stops working.
Once the Kubelet is down you can see kubectl get nodes that node is in state “NotReady”.
In addition if you describe your node kubectl describe $NODE you can see the status description is: “System OOM encountered”.
If you look on your pods kubectl get pods --all-namespaces you can see that pods are in state “Unknown” or in “NodeLost”.
Kubelet OOM errors should be avoided by all costs.
It causes to stop all pods on that node and its quite complicated for K8s to maintain high availability for applications in some cases.
For example for stateful sets with a single replica k8s cannot immediately move that pod to another node.
The reason is that k8s does not know how long the node with all its pods stays unavailable.
Therefore i like to share some best practice to avoid OOM problems in your AWS EKS clusters.
In a perfect world every pod exactly knows how many resources he needs and simply specifies it with the k8s ressources configuration.
If you use a deployment or statefulset it would look like:
…
resources:
requests:
memory: “500Mi”
cpu: “500m”
limits:
memory: “1000Mi”
cpu: “1000m”
…
Details can be found here: https://kubernetes.io/docs/concepts/configuration/manage-compute-resources-container/
Specifiying the required ressources helps k8s a lot to determine how many pods should be located on which node.
But still it may happen that OOM errors occur and kubelet dies.
The reasons are:
* There are some “kube-system” pods running installed by AWS without ressources being specified. Simply type “kubectl get pods -n kube-system” to see them.
* It may happen that pods use more than the limit of memory specified.
* If there are not enough nodes to schedule on these pods, k8s starts to overcommit nodes. Hoping that not all pods reach there limits on that node in parallel.
So we need to reserve some memory for the kubelet and the system namespaces.
Using Cloudformation you can simply set some extra arguments on the kubelet process:
--kubelet-extra-args "--node-labels=cluster=${ClusterName},nodegroup=${NodeGroupName} --kube-reserved memory=0.3Gi,ephemeral-storage=1Gi --system-reserved memory=0.2Gi,ephemeral-storage=1Gi --eviction-hard memory.available<200Mi,nodefs.available<10%"
In that case you reserve 300MB for the kube-system namespace and 200 MB for the system itself.
In addition if there are less than 200 MB available the eviction option uses the oom_killer to kill pods on that node to avoid OOM errors on the Kubelet.
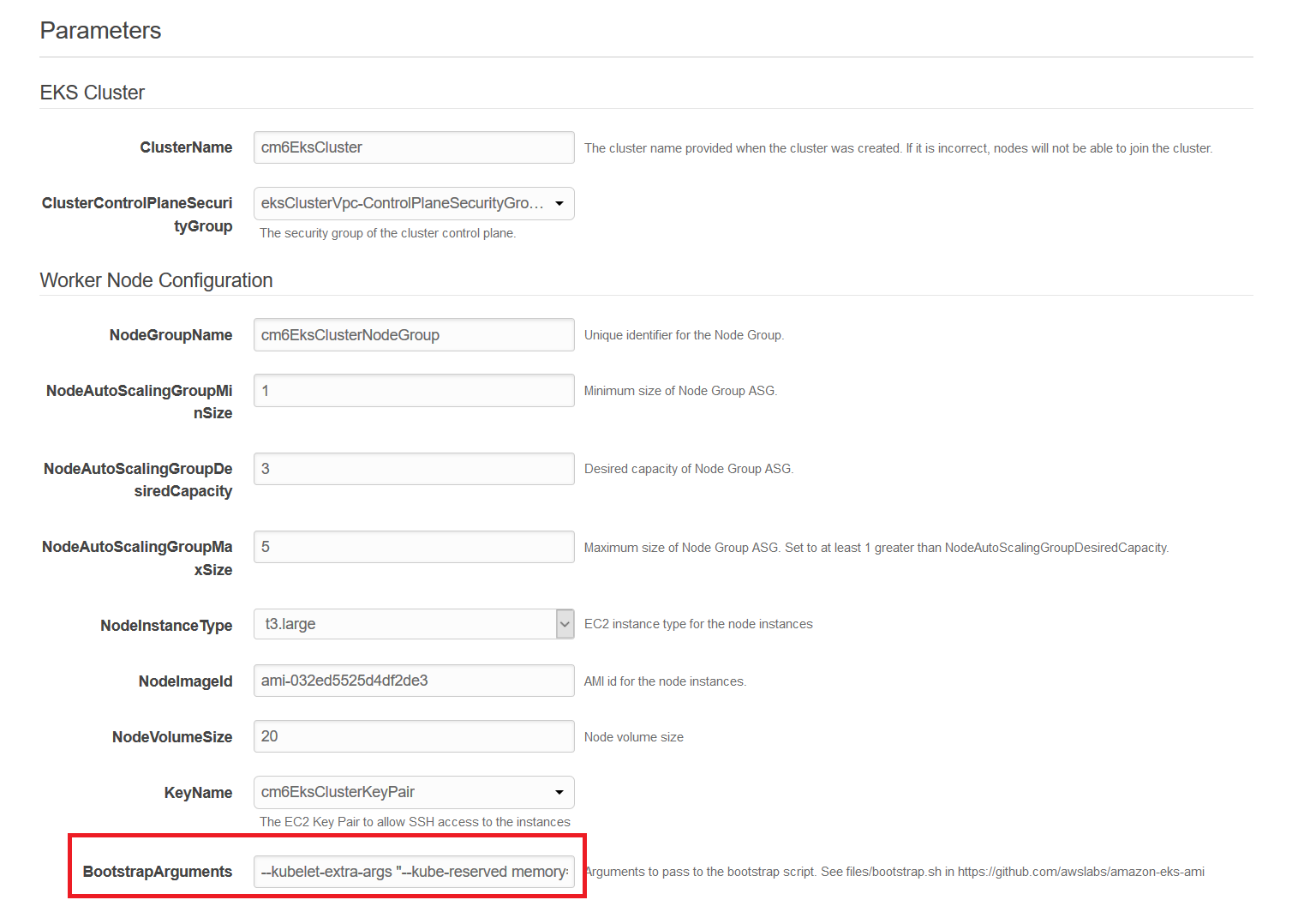
By default you specifiy the count and type of EC2 intances that you want to use in your cluster.
In the Cloudformation template you can specifiy the minimum, desired and maximum count of instances.
But the cluster simply gets started with desired count of instances. It will never use more instances than the desired count.
To achieve this you need to configure a k8s autoscaling component.
There is a nice guide which provides a step by step Howto: AWS EKS Autoscaling Guide
Once configured the autoscaler k8s automatically starts and stops EC2 instances based on your ressources needs.
Important limitation !
This only works if you set the ressource limits on your pods.
The reason is that once ressource limits set the pods go in state “pending” with a message that not enough memory is available.
If the autoscaler finds a pending pod with this condition it spawns a new node.
If you dont have ressource limits set the scheduler always tries to start these pods as k8s doesnt know how many ressources this pod needs.
Next the oom_killer will detect that not enough memory is left on that node and kills a pod.
Therefore you see killed and starting pods over and over again.
The autoscaler can never see a pod in pending state and therefore will not scale your EC2 autoscaling group to max level.
If you need to analyze OOM problems related to kubelet.
The following commands should help you find out more.
https://aws.amazon.com/de/eks/
https://eksworkshop.com/scaling/deploy_ca
https://github.com/kubernetes/autoscaler/tree/master/cluster-autoscaler/cloudprovider/aws
https://kubernetes.io/docs/tasks/administer-cluster/reserve-compute-resources/#kube-reserved
https://kubernetes.io/docs/tasks/administer-cluster/reserve-compute-resources/#system-reserved