


After some time, let’s move on to another topic around making OpenShift environments more developer friendly. This time we are going to look at what happens, when a system test actually failed, and how to enable developers to properly react.
First, as a quick reminder: When we talk about system tests here we mean integration tests that run against a complete OpenShift test deployment of some application/microservice, normally isolated in a separate OpenShift test project. Something like that:
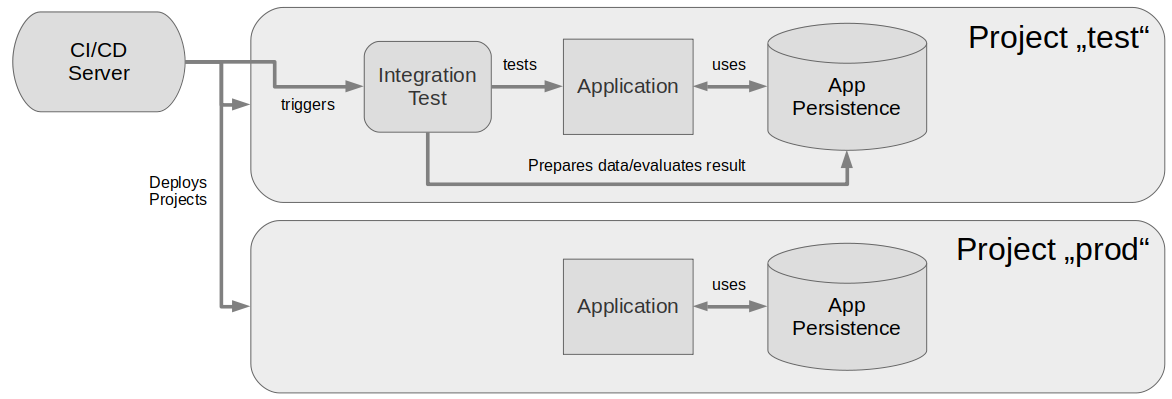
Here the environments “test” and “prod” are completely equal, except for the integration test that runs on “test”. Most likely they originate from the same infrastructure code. These system tests provide the most realistic environment for the cost of heavy resource usage and longer preparation time. However in most CI/CD systems we have such tests to validate the most essential functionality of a software under really production-like conditions.
So you have this system test that is executed magically on a stage of your CI/CD pipeline. Something goes wrong on that test, the Job fails. The error message in the job log in most cases will not make it absolutely clear why it happened. As a developer, what do you want to do first?
Right, you want to have a look at the test environment and analyze the problem. But, duh, the test environment is already gone. Your pipeline automatically scrapped it after the Job ended. Or the project and its resources are reused by the next Job that runs, thus now containing a different setup. In either way: The environment where your test failed is no more and you have very little capabilities to analyze what happened, beyond looking at the logs on your log aggregation site.
Yes, this is tricky. Of course best would be if every test run had its own environment that, if things go wrong, could just be kept for exhaustive analysis. Unfortunately cluster resources are scarce. So often there has to be some tradeoff. Here are some suggestions:
In almost every situation it is best to have every test run use a separate test project. This does not mean that you need to keep all those individual projects, they may get deleted afterwards. It just means that your test resources are absolutely individual for a specific run and are not overwritten by subsequent runs, a circumstance that ist mostly just causing confusion. It also enables other best practices further down the line.
Implement your system test process in a way that it organizes a small pool of “slots” for test projects, which are created and deleted ad-hoc. A new test run reserves a slot, thus can create a test project. If the job succeeds, the test project is deleted instantly and releases the slot. But if a test fails then the respective project will be kept for some time and the slot keeps being reserved. Now there are only 2 free “project slots” for the others to use while the developer of the failed job can research her issue.
Of course, once 2 jobs fail at the same time you are down to 1 operative slot, and that cannot be kept any more in case of failure. However, in many situations this strategy will allow your first 2 lucky developers with failed tests to do valuable analysis work. Yes, this is quite a special setup. If you don’t want to do it yourself, why not ask us? :-)
If you really need to be tight on resources: Keep the test project for some time but tune down all deployments in it to 0 pods, so that it effectively does not use CPU and memory any more. Yes, this will kill the state of the pods which would have been helpful too. But at least your developers can analyze the test setup and environment (which all too often is the cause for the problems by itself). And if really needed, your developer might be allowed to scale up the pods again and rerun the test to see what really happens.
Per default OpenShift builds put out the built images under a tag “latest”. If all your system tests run against a constant stream of “latest” application images then you might have trouble reconstructing which image a certain test ran against as time marches on and further tests are run by other people. This is even so if you keep the test project of a failed test, like described above.
There are some ways around this, which all end up by providing some sort of qualification of involved resources. If you follow our earlier recommendation of having individual projects for test runs you could copy the current “latest” image to an image stream tag in that project and use it to provide the image to your test deployment. This tag will not be overridden because other test runs use other projects, so the deployment keeps a stable image reference.
Or instead you might want to use Git commit ids instead for tags. This most likely introduces the need to auto-generate BuildConfigs (if you don’t already do that) as the target tag of BuildConfigs is unfortunately fixed and cannot be determined for each run. This also introduces the necessity for controlled pruning of old image tags, which however is no big deal with available “oc adm prune” options.
Maybe you just cannot preserve the environments of failed system tests. But even if that is not the case it is recommended to provide your developers with instructions how they can run the system tests themselves on their local machine. This is a prerequisite for writing these tests efficiently in the first place, so the developer does not need the pipeline to validate the test on early development stages. The same goes for a developer that analyzes a failed test which is already known to work.
Often this is still done by running the software locally without anything Docker or OpenShift. That involves the task of setting up several servers locally that are needed by your software: Application server, Database server, Messaging server and whatnot. This setup, which might take quite some time to get right, will almost always deviate from the actual test environment on OpenShift in many ways. So why not also use OpenShift locally to set everything up in there? That setup process is already defined for the CI/CD pipeline and could be reused.
This at first may sound like overkill, but tools like minishift in combination with a “Infrastructure as Code” approach for setting up application environments make it quite easy to accomplish. In the end the setup process will be by far less tedious and will resemble the real test environment much more.
In any case we recommend that your developers should be able to run their application in a local OpenShift, so why not also use that for local system test execution?