


Let’s move on with this little series about how OpenShift environments may fall short in terms of developer experience.
Today we focus on the role that system tests have in an OpenShift infrastructure and what might possibly go wrong here testdata-wise.
You might call these tests different than we do: integration tests, module tests, E2E tests. What we mean is any test that runs against a deployment of your software which exists in exactly the same fashion in production. In our situation here this means: Against a deployment of your application image inside some OpenShift project. And most likely the test itself is executed by some CI/CD server that you use, for example Jenkins.
Now, imagine a “system under test” that uses some database to store and read data. What would a system test for that service typically do? Might look like this:
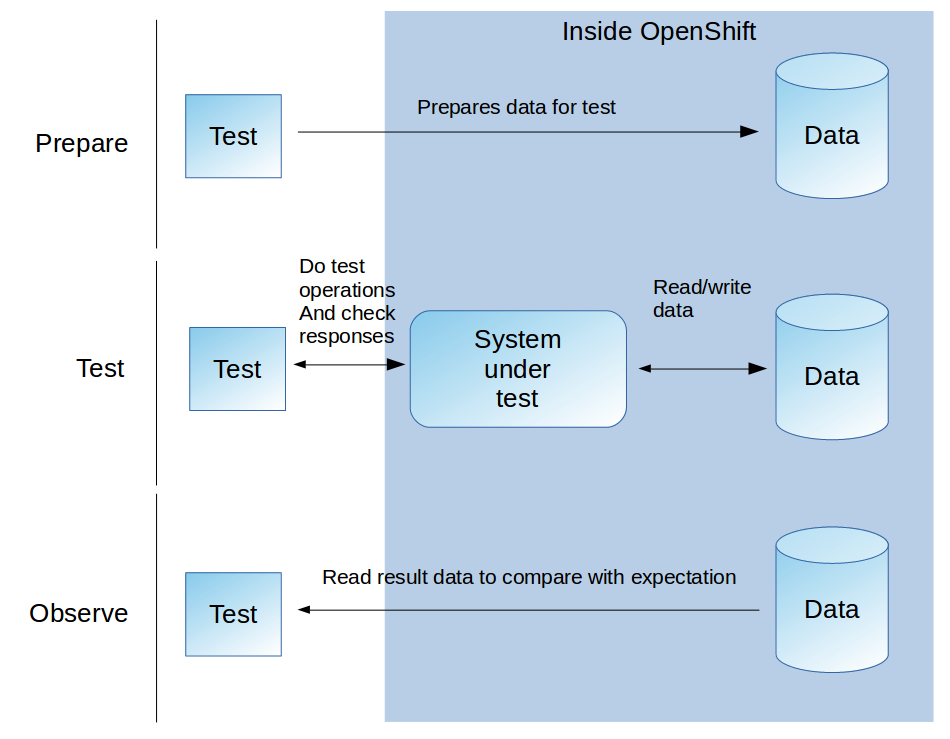
When running something like that in OpenShift it is just natural that you would use a database server that is right inside your OpenShift project, just like implied by the illustration. The OpenShift image catalog has some nice ready-to-use MySQL/PostgreSQL images for that. It is the easiest way to provide a database for testing purposes, way more manageable than anything outside and exclusively dedicated for your test. You could even use some ephemeral database server that on each test starts with a clean state.
But: Can your Systemtests access this database directly for the preparation task? Chances are they can’t if they are run by something outside your very OpenShift project, like some external Jenkins or even an OpenShift-hosted Jenkins happening to be in the wrong project. Remember: In most productive OpenShift clusters services are private to the local project. For other types of communication you would be able to use a route for exposing the service to the outside, but most databases talk non-HTTP-protocols which wont work via route.

This is a bad situation because it makes your system test setup way more difficult. Your data preparation will not be doable specifically for each test. Instead you might resort to preparing data for all your tests together before everything is run. You could provide your DB deployment with some big initializing SQL script. This of course means that your system tests may influence each other data-wise. Want to add another test? Take good care that the data preparation and manipulation for it will not make other tests fail (or, even worse, succeed for the wrong reasons). Needless to say that this reduces your ability to scale out your system tests to larger numbers without running into maintenance nightmares preparing their data.
Sure, you could resort to use some database outside of OpenShift again, but the capability to run dedicated test database servers inside of it is too precious to let go easily. So what are the alternatives:
Prepare some proxying service for these databases so you can talk to them via HTTP, based on GraphQL for example. Could be deployed alongside your application into the systemtest project. Then let your system tests talk to the database via the proxy instead of directly.
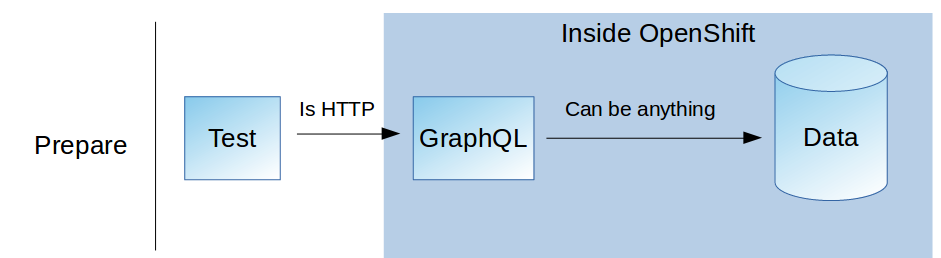
This might work great and is OK for singular occasions but has more of a workaround than anything else. You’re adding another service to your deployment that needs to be developed, deployed, configured and secured, just to fill that little gap. So on to something more elegant …
…where it actually belongs and has unlimited network access to the resources there. This solution is for Jenkins: Use the Kubernetes Plugin to run the system test in a jenkins slave node that itself runs right inside OpenShift as a dedicated pod. If you use the Jenkins stock image from OpenShift: This plugin is already preinstalled and -configured here.
Whole architecture then looks like this:
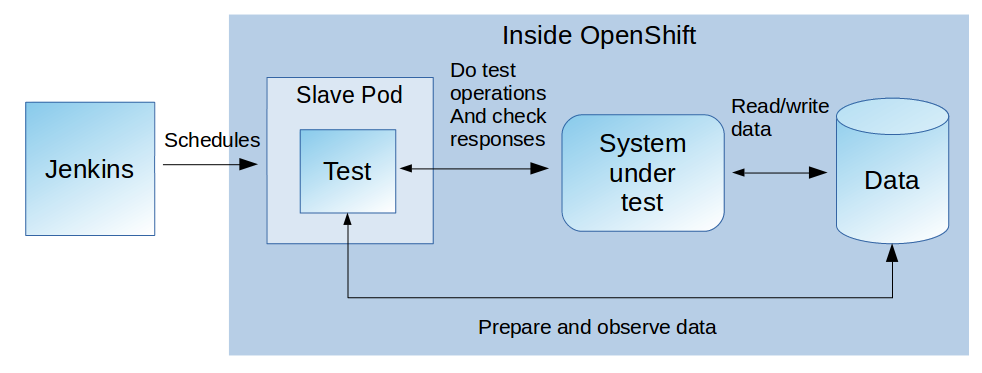
To set this up you use the “podTemplate” and “node” commands in your Jenkins pipeline that come with the plugin. The first one defines the pod that runs your slave. Here you configure it to use the OpenShift project where your system test happens and where it has direct access to the services located there. The second command actually instantiates a node based on the defined template and is able to execute custom pipeline functionalities inside of it.
Here’s an example from a Jenkinsfile script:
podTemplate(label: 'systemtest', cloud: 'openshift',
inheritFrom: 'maven', namespace: 'my-systemtest-project') {
node('systemtest') {
... your maven-driven test execution goes here ...
}
}
In short: You build a pod template for a jenkins slave here and give it the label “systemtest”. You inherit most settings from a default template called “maven”. This pod is configured to run inside OpenShift project “my-systemtest-project”.
After that you start a concrete slave pod with the “node” command and address your previously defined pod template via label. Have a look at the Kubernetes Plugin documentation to see what the syntax means in detail.
Setting this up may be a bit fiddly at start. Some tipps when working with pod templates: