


check_logfiles is a Plugin for Nagios which scans log files for specific patterns.
The conventional plugins which scan log files are not adequate in a mission critical environment. Especially the missing ability to handle logfile rotation and inclusion of the rotated archives in the scan allow gaps in the monitoring. Check_logfiles was written because these deficiencies would have prevented Nagios from replacing a propritetary monitoring system.
Usually you call the plugin with the –config option which gets the name of a configuration file:
nagios$ check_logfiles --config
OK - no errors or warningsIn it’s most simple form check_logfiles can get all the essential parameters as command line options. However, not all features can be utilized in this case.
nagios$ check_logfiles --tag=ssh --logfile=/var/adm/messages \
--rotation SOLARIS \
--criticalpattern 'Failed password for root'
OK - no errors or warnings |ssh=1722;0;0;0
nagios$ check_logfiles --tag=ssh --logfile=/var/adm/messages \
--rotation SOLARIS \
--criticalpattern 'Failed password for root'
CRITICAL - (1 errors in check_logfiles.protocol-2007-04-25-20-59-20) - Apr 25 20:59:15 srvweb8 sshd[10849]: [ID 800047 auth.info] Failed password for root from 172.16.224.11 port 24206 ssh2 |ssh=2831;0;1;0In principle check_logfiles scans a log file until the end-of-file is reached. The offset will then be saved in a so-called seekfile. The next time check_logfiles runs, this offset will be used as the starting position inside the log file. In the event that a rotation has occurred in the meantime, the rest of the rotated archive will be scanned also.
For the most simple applications it is sufficient to call check_logfile with command line parameters. More complex scan jobs can be described with a config file.
The definitions in this file are written with Perl-syntax. There is a distinction between global variables which influence check_logfiles as a whole and variables which are related to the single searches. A “search” combines where to search, what to search for, which weight a hit has, which action will be triggered in case of a hit, and so on…
| $seekfilesdir | A directory where files with status information will be saved after a run of check_logfiles. This status information helps check_logfiles to remember up to which position the log file has been scanned during the last run. This way only newly written lines of log files will be read. | The default is /tmp or the directory which has been specified with the –with-seekfiles-dir of ./configure. |
| $protocolsdir | A directory where check_logfiles writes protocol files with the matched lines. | The default is /tmp or the directory which has been specified with the –with-protocol-dir of ./configure. |
| $protocolretention | The lifetime of protocol files in days. After these days the files are deleted automatically | The default is 7 days. |
| $scriptpath | A list of directories where the triggered scripts can be found.(Separated by : under Unix and ; under Windows) | The default is /bin:/usr/bin:/sbin:/usr/sbin or the directories which has been specified with the –with-trusted-path of ./configure. |
| $MACROS | A hash with user-defined macro definitions. | see below. |
| $prescript | An external script which will be executed during the startup of check_logfiles. The macro $CL_TAG gets the value “startup”. $prescriptparams, $prescriptstdin and $prescriptdelay may be used like scriptparams, scriptstdin and scriptdelay. | |
| $postscript | An external script which will be executed before the termination of check_logfiles. The macro $CL_TAG$ gets the value “summary”. $postscriptparams, $postscriptstdin and $postscriptdelay may be used like scriptparams, scriptstdin and scriptdelay. | |
| $options | A list of options which control the influence of pre- and postscript. Known options are smartpostscript, supersmartpostscript, smartprescript and supersmartprescript. With the option report=”short|long|html” you can customize the plugin’s output. With report=long/html, the plugin’s output can possibly become very long. By default it will be truncated to 4096 characters (The amount of data an unpatched Nagios is able to process). The option maxlength can be used to raise this limit, e.g. maxlength=8192. The option seekfileerror defines the errorlevel, if a seekfile cannot be written, e.g. seekfileerror=unknown (default:critical). The same applies to protocolfileerror (default: ok). Usually the last error message will be shown in the first line of the output. With preview=5 you can tell check_logfiles to show for example the last 5 hits. (default is: preview=1) | |
| @searches | An array whose elements (hash references) describe the actual work of check_logfiles. The keys for these hash references can be found in the next table. |
The single searches are further specified by the following parameters:
| tag | A unique identifier. |
| logfile | The name of the log file to scan. |
| archivedir | The name of the directory where archives will be moved to after a log file rotation. The default is the directory where the logfile resides. 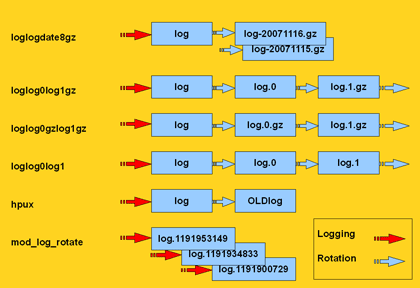 |
| rotation | One of the predefined methods or a regular expression, which helps identify the rotated archives. If this key is missing, check_logfiles assumes that the log file will be simply overwritten instead of rotated. |
| type | One of “rotating” (default if rotation was given), “simple” (default if no rotation was given), “virtual” (for files which will strictly be scanned from the beginning), “errpt” (if instead of a logfile the output of the AIX errpt command should be scanned), “ipmitool” (if the IPMI System Event Log should be scanned), “oraclealertlog” (if the alertlog of an Oracle database should be scanned through a database connection) or “eventlog” if the windows Eventlog should be scanned. |
| criticalpatterns | A regular expression or a reference to an array of such expressions. If one of these expressions matches a line in the logfile, this is considered a critical error. If the expression begins with a “!”, then the meaning is reversed. It counts as a critical error if no match for this pattern is found. |
| criticalexceptions | One or more regular expressions which invalidate a preceding match of criticalpatterns. |
| warningpatterns | Corrensponds to criticalpatterns, except a warning instead of a critical error is created. |
| warningexceptions | see above |
| okpatterns | A regular expression or a reference to an array of such expressions. If one of these expressions matches a line in the logfile, all previous found warnings and criticals are discarded. |
| script | If a pattern matches, this script will be executed. It must reside under one of the directories specified in $scriptpath. The script gets plenty of information about the hit via environment variables. |
| scriptparams | Yo can provide command line parameters for the script here. They may contain macros. If $script is a code reference, $scriptparams must be a pointer to an array. |
| scriptstdin | If the script expects input through stdin, you can describe it here. The string may also contain macros. |
| scriptdelay | After the script has finished, check_logfiles may sleep for <delay> seconds before continuing it’s work. |
| options | This is a string with a comma-separated list of options which let you fine-tune the search. Each option can be switched off be preceeding it’s name with “no”. The options in detail are explained in the next table: |
| template | Instead of a tag , a search can also be identified by a template name. If you call check_logfiles with the –tag option, the according search will be run as if it was defined with a tagname. See examples. |
Options
| [no]script | Controls whether a script can be executed. | default: off |
| [no]smartscript | Controls whether exitcode and output of the script shall be treated like an additional match. | default: off |
| [no]supersmartscript | Controls whether exitcode and output of the script should replace the triggering match. | default: off |
| [no]protocol | Controls whether the matching lines are written to a protocol file for later investigation. | default: on |
| [no]count | Controls whether hits are counted and decide over the final exit code. If not you can use check_logfiles also just to execute the triggered scripts. | default: on |
| [no]syslogserver | If set, only lines originating from the local host are taken into account. This is important if check_logfiles runs on a syslog server where many other hosts report their events to. | default: off |
| [no]syslogclient=string | A prefilter. Only lines matching the string are further examined. | default:off |
| [no]perfdata | Controls whether performance data should be added to the output. | default: on |
| [no]logfilenocry | Controls how to react, if the log file does not exist. By default this is a reason for an UNKNOWN error. If nologfilenocry is set, the missing log file will be acquiesced. | default: on |
| logfilemissing | Is used to change this UNKNOWN to a different status. With logfilemissing=critical you can have check_file_existence-functionality. | default: unknown |
| [no]case | Controls whether regular expressions are case-sensitive | default: on |
| [no]sticky[=seconds] | Controls whether an error is propagated through successive runs of check_logfiles. Once an error was found, the exitcode will be non-zero until an okpattern resets it or until the error expires after <second> seconds. Do not use this option until you know exactly what you do. | default: off |
| [no]savethresholdcount | Controls whether the hit counter will be saved between the runs. If yes, hit numbers are added until a threshold is reached (criticalthreshold). Otherwise the run begins with resetted counters. | default: on |
| [no]encoding=string | The logfile is encoded in Unicode. (e.g. ucs-2) | default: off |
| [no]maxlength=number | Truncates very long lines at the <number>-th character | default: off |
| [no]winwarncrit | Can be used instead of patterns to find all events of type WARNING/ERROR in the Windows-Eventlog | default: off |
| [no]criticalthreshold=number | A number which denotes how many lines have to match a pattern until they are considered a critical error. | default: off |
| [no]warningthreshold=number | A number which denotes how many lines have to match a pattern until they are considered a warning. | default: off |
| [no]allyoucaneat | With this option check_logfiles scans the entire logfile during the initial run (when no seekfile exists) | default: off |
| [no]eventlogformat | This option allows you to rewrite the message text of a Windows event. Normally it only consists of the field Message. You can enrich this string with additional information (EventID, Source,….)Scroll down for details. | default: off |
| [no]preferredlevel | If warningpattern and criticalpattern were chosen in a way that a specific line matches both of them (so the output looks like “1 error, 1 warning”), you can use this option to count only one of them. (e.g. with preferredlevel=critical the output would be “1 error”). | default: off |
| [no]randominode | This is used for a very special case, where the inode of the logfile is constantly changing. (for example because with every appended line the logfile is written entirely new) | default: off |
| [no]randomdevno | This is used for a very special case, where the device number of the device, where the logfile resides, is constantly changing. (this can happen with lvm and kvm disks) | default: off |
| [no]savestate | This option forces the creation of a seekfile for searches of type virtual | default: off |
| [no]capturegroups | If a pattern contains round parentheses for grouping, the variables $1, $2, … are stored in the macros CL_CAPTURE_GROUP1, CL_CAPTURE_GROUP2, … The number of these macros (the highest counter of CL_CAPTURE_GROUPx) can be found in CL_CAPTURE_GROUPS. These macros are best used as environment variables in a handler script. | default:off |
| maxage=timerange | Can be used for an extra check regarding the last modification time of the logfile. Timerange is: <number>[s|m|h]. If the logfile was not changed since this time (ex. 2h) then this counts as CRITICAL. | default:off |
Predefined macros
| $CL_USERNAME$ | The name of the user executing check_logfiles |
| $CL_HOSTNAME$ | The hostname without domain |
| $CL_DOMAIN$ | The DNS-domain |
| $CL_FQDN$ | Both together |
| $CL_IPADDRESS$ | The IP-adress |
| $CL_DATE_YYYY$ | The current year |
| $CL_DATE_MM$ | The current month (1..12) |
| $CL_DATE_DD$ | The day of the month |
| $CL_DATE_HH$ | The current hour (0..23) |
| $CL_DATE_MI$ | The current minute |
| $CL_DATE_SS$ | The current second |
| $CL_DATE_CW$ | The current calendar week (ISO 8601:1988) |
| $CL_SERVICEDESC$ | The name of the config file without extension. |
| $CL_NSCA_SERVICEDESC$ | the same |
| $CL_NSCA_HOST_ADDRESS$ | The local address 127.0.0.1 |
| $CL_NSCA_PORT$ | 5667 |
| $CL_NSCA_TO_SEC$ | 10 |
| $CL_NSCA_CONFIG_FILE$ | send_nsca.cfg |
| The following macros change their value during the runtime. | |
| $CL_TAG$ | The tag of the current search ($CL_tag$ is the tag in minor letters) |
| $CL_TEMPLATE$ | The name of the template used (if any). |
| $CL_LOGFILE$ | The file to be scanned next |
| $CL_SERVICEOUTPUT$ | The last matched line. |
| $CL_SERVICESTATEID$ | The error level as a number 0..3 |
| $CL_SERVICESTATE$ | The error level as a word (OK, WARNING, CRITICAL, UNKNOWN) |
| $CL_SERVICEPERFDATA$ | The Performancedata. |
| $CL_PROTOCOLFILE$ | The file where all matching lines are written. |
These macros are also available in scripts called out of check_logfiles. Their values are stored in environment variables, whose names are derived from the macro’s names. The preceding CL_ is replaced by CHECK_LOGFILES_. You can also access user defined macros. Their names are also prefixed with CHECK_LOGFILES_.
nagios:~> cat check_logfiles.cfg
$scriptpath = '/usr/bin/my_application/bin:/usr/local/nagios/contrib';
$MACROS = {
MY_FUNNY_MACRO => 'hihihihohoho',
MY_VOLUME => 'loud'
};
@searches = (
{
tag => 'fun',
logfile => '/var/adm/messages',
criticalpatterns => 'a funny pattern',
script => 'laugh.sh',
scriptparams => '$MY_VOLUME$',
options => 'noprotocol,script,perfdata'
},
);
nagios:~> cat /usr/bin/my_application/bin/laugh.sh
#! /bin/sh
if [ -n "$1" ]; then
VOLUME=$1
fi
printf "It is %d:%d and my status is %s\n" \
$CHECK_LOGFILES_DATE_HH \
$CHECK_LOGFILES_DATE_MI \
$CHECK_LOGFILES_SERVICESTATE
printf "I found something funny: %s\n" "$CHECK_LOGFILES_SERVICEOUTPUT"
if [ "$VOLUME" == "Xloud" ]; then
echo "$CHECK_LOGFILES_MY_FUNNY_MACRO" | tr 'a-z' 'A-Z'
else
echo "$CHECK_LOGFILES_MY_FUNNY_MACRO"
fi
printf "Thank you, %s. You made me laugh.\n" "$CHECK_LOGFILES_USERNAME"The number of scanned lines as well as the number of pattern matches (critical, warning and unknown) are appended to the plugin’s output in performance data format. You can suppress this by using the noperfdata option.
nagios$ check_logfiles --logfile /var/adm/messages \
--criticalpattern 'Failed password' --tag ssh
CRITICAL - (4 errors) - May 9 11:33:12 localhost sshd[29742] Failed password for invalid user8 ... |ssh_lines27 ssh_warnings=0 ssh_criticals=4 ssh_unknowns=0
nagios$ check_logfiles --logfile /var/adm/messages \
--criticalpattern 'Failed password' --tag ssh --noperfdata
CRITICAL - (2 errors) - May 9 11:58:48 localhost sshd[29813] Failed password for invalid user8 ...It is possible to execute external scripts out of check_logfiles. This can be at the startup phase ($prescript), before termination ($postscript) or every time a pattern matches a line. See example above. With the option “smartscript” output and exitcode of the script are treated like a match in the logfile and reflected in the overall result. The option “supersmartscript” makes output and exitcode of the script replace those of the triggering match. Pre- and Postscript declared as supersmart scripts directly influence the process of check_logfiles. The option “supersmartprescript” causes an immediate abort of check_logfiles if the prescript has a non-zero exit code. In this case output and exitcode of check_logfiles correspond to those of the prescript.
With the option “supersmartpostscript” output and exitcode of check_logfiles can be determined by the postscript. Thus a more meaningful output is possible.
If you have just one service which uses check_logfiles you can hard-code the config file in your services.cfg/nrpe.cfg
define service {
service_description check_sanlogs
host_name oaschgeign.muc
check_command check_nrpe!check_logfiles
is_volatile 1
check_period 7x24
max_check_attempts 1
...
}
define command {
command_name check_nrpe
command_line $USER1$/check_nrpe -H $HOSTADDRESS$ -c $ARG1$
}
command[check_logfiles]=/opt/nagios/libexec/check_logfiles
--config logdefs.cfgIf multiple services are based on check_logfiles you need multiple config files. I propose to name them after the service_description. In the following example we would have a directory cfg.d with config files solaris_check_sanlogs and solaris_check_apachelogs.
define service {
service_description logfilescan
register 0
is_volatile 1
check_period 7x24
max_check_attempts 1
...
}
define service {
service_description solaris_check_sanlogs
host_name oaschgeign.muc
check_command
check_nrpe_arg!20!check_logfiles!cfg.d/$SERVICEDESC$
contact_group sanadmin
use logfilescan
}
define service {
service_description solaris_check_apachelogs
host_name oaschgeign.muc
check_command
check_nrpe_arg!20!check_logfiles!cfg.d/$SERVICEDESC$
contact_group webadmin
use logfilescan
}
define command {
command_name check_nrpe_arg
command_line $USER1$/check_nrpe
-H $HOSTADDRESS$ -t $ARG1$ -c $ARG2$ -a $ARG3$
}The corresponding line in the host’s nrpe.cfg looks like that:
[check_logfiles]=/opt/nagios/libexec/check_logfiles --config $ARG1$If you use nsclient++ under Windows, the entry in the NSC.ini looks like that:
check_logfiles=C:\Perl\bin\perl C:\libexec\check_logfiles --config $ARG1$If you want to scan the alert log of an oracle database without having access to the database server on the operating system level (e.g. it is a Windows server or you are not allowed to log in to a Unix server for security reasons) and therefore no access to the alert file, then this file can be mapped to a database table. The contents of the file are then visible through a database connection by executing SQL SELECT statements. If you specify the type “oraclealertlog” in a check_logfiles configuration, this method is used to scan the alert log. You need some extra parameters in the configuration.
# extra parameters in the configuration file
@searches = ({
tag => 'oratest',
type => 'oraclealertlog',
oraclealertlog => {
connect => 'db0815', # connect identifier
username => 'nagios', # database user
password => 'hirnbrand', # database password
},
criticalpatterns => [
...Mapping external files to database tables is possible since Version 9. Use this script to prepare your database:
create_alert_log_table.sql
Installation of the Perl-Modules DBI and DBD::Oracle (http://search.cpan.org/~pythian/DBD-Oracle-1.74/lib/DBD/Oracle.pm).
The eventlog of Windows systems can be processed by check_logfiles like any other logfile. Each event is treated like a line. Also only those events get analyzed which appeared since the last run of check_logfiles.
In it’s most simple form an eventlog search looks like this:
@searches = ({
tag => 'evt_sys',
type => 'eventlog',
criticalpatterns => ['error', 'fatal', 'failed', ....
# logfile anzugeben ist hier nicht nötig, da sinnlos.If the evaluation of events should not be based on patterns, but the windows-internal stati WARNING and ERROR, use the option winwarncrit.
@searches = ({
tag => 'evt_sys',
type => 'eventlog',
options => 'winwarncrit',It is also possible to analyze only a subset of all the events in the eventlog. You can use include- and exclude-filters for that.
@searches = ({
tag => 'winupdate',
type => 'eventlog',
eventlog => {
eventlog => 'system',
include => {
source => 'Windows Update Agent',
eventtype => 'error,warning',
},
exclude => {
eventid => '15,16',
},
},
criticalpatterns => '.*',With these settings, only those events are fetched from the eventlog which comply with the following requirements:
* The System-Eventlog is used
* Only events with the source “Windows Update Agent” are read.
* Only errors and warnings are read.
* Events with the IDs 15 and 16 are discarded.
Please be aware that the single include-requirements are combined by logical AND and the exclude-requirements are combined by logical OR. The comma-separated lists are always combined by OR.
filter = ((source == "Windows Update Agent") AND ((eventtype == "error") OR (eventtype == "warning"))) AND NOT ((eventid == 15) OR (eventid == 16))You can change this behavior with the key “operation”. It takes the arguments “and” or “or”.
@searches = ({
tag => 'winupdate',
type => 'eventlog',
eventlog => {
eventlog => 'system',
include => {
source => 'Windows Update Agent',
eventtype => 'error,warning',
operation => 'or',
},
exclude => {
eventid => '15,16',
},
},
criticalpatterns => '.*',Now the filter means: “Windows Update Agent” OR (“error” OR “warning”)
type => 'eventlog',
eventlog => {
eventlog => 'system', # system (default), application, security
include => {
source => 'Windows Update Agent', # die Herkunft (Source) des Events
eventtype => 'error,warning', # error, warning, info, success, auditsuccess, auditfailure
operation => 'or' # die logische Verknüpfung. Default ist "and"
},
exclude => {
eventid => '15,16', # die ID des Events
},
},Filters can also be used in commandline-mode.
check_logfiles --type "eventlog:eventlog=application,include,source=Windows Update Agent,eventtype=error,eventtype=warning,exclude,eventid=15,eventid=16"With another option it is possible to rewrite an event’s message text. Normally check_logfiles sees the field Message when it tries to match a pattern. This is also what is shown in the plugin’s output. The option eventlogformat can be used to include the fields EventType, Source, Category, Timewritten and TimeGenerated in the output.
EventType: ERROR
EventID: 16
Source: W32Time
Category: None
Timewritten: 1259431241
TimeGenerated: 1259431241
Message: Der NtpClient verfügt über keine Quelle mit genauer Zeit.options => 'eventlogformat="%w src:%s id:%i %m"',With this eventlogformat the message text of the above event will be rewritten to:
2009-11-28T19:04:16 src:W32Time id:16 Der NtpClient verfügt über keine Quelle mit genauer Zeit.The formatstring knows the following tokens:
%t EventType
%i EventID
%s Source
%c Category
%w Timewritten
%g TimeGenerated
%m MessageWith %<number>m you can shorten the message to number characters.
Windows operating systems prior to Windows Vista use the standard (EVT) event logging format. Windows Vista and later clients and Windows 2008 and later servers use the newer EVTX (Crimson) event log format. And, what’s more important, there are not only the Windows Logs “application”, “system”, “security”, but a great number of Application and Services Logs.
Examples are Microsoft-Windows-PowerShell/Operational, Microsoft/Exchange/HighAvailability/Operational and many more.
Since version 3.7 check_logfiles can search these channels, too.
@searches = ({
tag => "msps",
type => "wevtutil",
criticalpatterns => ["Microsoft", "PowerShell.*(ready|bereit)" ],
warningpatterns => ["PowerShell.*(started|gestartet)" ],
wevtutil => {
eventlog => "Microsoft-Windows-PowerShell/Operational",
}
});Here you can find example configurations for several scenarios.
Check_logfiles wird unter der GNU General Public License zur Verfügung gestellt.
Gerhard Laußer (gerhard.lausser@consol.de) beantwortet gerne Fragen zu diesem Plugin.