


check_logfiles ist ein Plugin für Nagios, das Logfiles auf bestimmte Muster hin durchsucht.
Die in den offiziellen Nagios-Plugins enthaltenen Scripts sind für den Einsatz in einem unternehmenskritischen Umfeld nur bedingt geeignet. Insbesondere die fehlende Einbeziehung von rotierten Logdateien in den Suchvorgang ermöglicht das Entstehen von Lücken in der Überwachung. check_logfiles entstand, weil diese Mängel das Aus für die Ablösung eines proprietären Systems durch Nagios bedeutet hätten.
Aufgerufen wird das Script normalerweise mit dem Parameter –config, der als Wert den Namen einer Konfigurationsdatei bekommt:
nagios$ check_logfiles --config
OK - no errors or warningsIn seiner einfachsten Form kann check_logfiles aber auch alle nötigen Parameter per Kommandozeilenoptionen erhalten. Mit dieser Form des Aufrufs sind allerdings nicht sämtliche Möglichkeiten des Plugins ausschöpfbar.
nagios$ check_logfiles --tag=ssh --logfile=/var/adm/messages \
--rotation SOLARIS \
--criticalpattern 'Failed password for root'
OK - no errors or warnings |ssh=1722;0;0;0
nagios$ check_logfiles --tag=ssh --logfile=/var/adm/messages \
--rotation SOLARIS \
--criticalpattern 'Failed password for root'
CRITICAL - (1 errors in check_logfiles.protocol-2007-04-25-20-59-20) - Apr 25 20:59:15 srvweb8 sshd[10849]: [ID 800047 auth.info] Failed password for root from 172.16.224.11 port 24206 ssh2 |ssh=2831;0;1;0Grundsätzlich funktioniert check_logfiles so, dass jede Logdatei bis zum Ende durchsucht wird. Die erreichte Position innerhalb der Datei wird in einem sogenannten Seekfile gespeichert. Beim nächsten Lauf von check_logfiles wird die Logdatei dann ab dieser gemerkten Position weitergelesen. Sollte es in der Zwischenzeit zu einer Rotation der Logdatei gekommen sein, dann wird auch der Rest der wegrotierten Datei durchsucht.
Für die einfachsten Anwendungsfälle wird check_logfiles mit Kommandozeilenparametern aufgerufen. Komplexere Szenarien mit mehreren Pattern oder mehreren Logfiles werden durch eine Konfigurationsdatei beschrieben.
Die Variablendefinitionen in dieser Datei werden in Perl-Syntax geschrieben. Es wird unterschieden zwischen globalen Variablen, die den gesamten Lauf von check_logfiles betreffen und solchen Variablen, die einen sogenannten “search” betreffen, derer es mehrere geben kann. Ein “search” fasst zusammen, wo gesucht wird, wonach gesucht wird, welche Relevanz ein Treffer hat, welche Aktion ggf. bei einem Treffer ausgelöst wird, usw.
| $seekfilesdir | Ein Verzeichnis, in dem Statusdateien nach einem Lauf von check_logfiles geschrieben werden. Diese Dateien enthalten Informationen darüber, bis zu welcher Zeile eine Logdatei gelesen und untersucht wurde. Beim nächsten Lauf von check_logfiles sorgen diese Informationen dafür, dass nur die neu hinzugekommenen Zeilen in der Logdatei analysiert werden. Die Defaulteinstellung ist /tmp oder das Verzeichnis, welches bei ./configure mit with-seekfiles-dir angegeben wurde. |
| $protocolsdir | Ein Verzeichnis, in dem check_logfiles bei jedem Lauf die gefundenen Zeilen in eine Protokolldatei schreibt (sofern dieses gewünscht ist). Die Defaulteinstellung ist /tmp oder das Verzeichnis, welches bei ./configure mit with-protocol-dir angegeben wurde. |
| $protocolretention | Die Anzahl der Tage, die die maximale Lebensdauer einer Protokolldatei ausdrückt. Nach Verstreichen dieser Tage wird die Datei automatisch gelöscht. Die Defaulteinstellung ist 7 Tage. |
| $scriptpath | Eine Liste von Verzeichnissen (getrennt durch Doppelpunkt (Unix) bzw. Strichpunkt (Windows)), in denen Scripts liegen, welche beim Auffinden bestimmter Muster in der Logdatei ausgeführt werden (sofern dies gewünscht ist). Die Defaulteinstellung ist /bin:/usr/bin:/sbin:/usr/sbin oder das Verzeichnis, welches bei ./configure mit with-trusted-path angegeben wurde. |
| $MACROS | Ein Hash, in dem eigene Macrodefinitionen eingetragen werden. siehe unten. |
| $prescript | Ein Script, welches in der Startphase von check_logfiles aufgerufen wird. Es hat noch nichts mit der späteren Suche nach Mustern zu tun, kann aber z.B. verwendet werden, um eine Applikation zum Leeren ihres Logbuffers zu zwingen. Der Macro $CL_TAG erhält den Wert “startup”. $prescriptparams, $prescriptstdin und $prescriptdelay können analog zu scriptparams, scriptstdin und scriptdelay verwendet werden. |
| $postscript | Ein Script, welches zum Abschluss von check_logfiles aufgerufen wird. Es kann verwendet werden, um das Gesamtergebnis des Laufs zu verarbeiten, wenn bei vielen zu erwartenden Treffern keine Einzelverarbeitung gewünscht wird. Der Macro $CL_TAG erhält den Wert “summary”. $postscriptparams, $postscriptstdin und $postscriptdelay können analog zu scriptparams, scriptstdin und scriptdelay verwendet werden. |
| $options | Eine Liste von Optionen, die den Einfluss von Pre- und Postscript regeln. Siehe Abschnitt “Scripts”. Mögliche Werte sind smartpostscript, supersmartpostscript, smartprescript und supersmartprescript. Mit der Option report=”short|long|html” kann man die Ausgabe des Plugins gestalten. Verwendet man report=long/html, so kann die Ausgabe des Plugins u.U. sehr lang werden. Defaultmässig wird diese nach 4096 Zeichen abgebrochen (Soviel wie ein ungepatchtes Nagios einlesen kann). Mit der Option maxlength lässt sich dieses Limit erhöhen, z.B. maxlength=8192. Die Option seekfileerror bestimmt die Schwere des Fehlers, wenn ein seekfile nicht geschrieben werden kann, z.B. seekfileerror=unknown (default:critical). Gleiches gilt für protofolfileerror (default: ok). Üblicherweise wird in der 1. Zeile des Outputs die zuletzt gefundene Fehlermeldung ausgegeben. Mit preview=5 erscheint z.b. eine Liste der letzten 5 Treffer. (default ist: preview=1) |
| @searches | Ein Array, das einen oder mehrere Einträge (Hashreferenzen) besitzt, welche die eigentliche Aufgabe von check_logfiles beschreiben. Die Schlüsselwerte für diese Hashes werden in der folgenden Tabelle beschrieben: |
Searches werden durch die folgenden Einstellungen genauer spezifiziert:
| tag | Ein eindeutiger Bezeichner. |
| logfile | Der Name der Logdatei, die durchsucht werden soll. |
| archivedir | Das Verzeichnis, in welchem sich die wegrotierten Logfiles befinden. Defaultmäßig ist das das Verzeichnis, in dem sich die Logdatei befindet. |
| rotation | Eine der vordefinierten Methoden oder ein regulärer Ausdruck, mit deren Hilfe sich in $archivedir die rotierten Logfiles identifizieren lassen. Fehlt dieser Eintrag, dann wird davon ausgegangen, dass die Logdatei nicht wegrotiert, sondern einfach überschrieben wird. 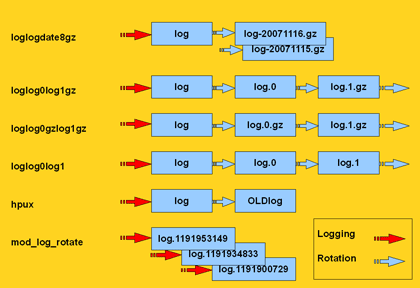 |
| type | Einer der Werte “rotating” (default, wenn rotation angegeben wurde), “simple” (default, wenn rotation fehlt), “virtual” (für Dateien, die grundsätzlich komplett durchsucht werden sollen), “errpt” (Wenn anstelle einer echten Datei die Ausgabe des errpt-Kommandos unter AIX durchsucht werden soll), “ipmitool” (Wenn das IPMI System Event Log durchsucht werden soll), “oraclealertlog” (Wenn durch eine Datenbankverbindung das Alertlog einer Oracle-DB ausgelesen werden soll) oder “eventlog”, wenn unter Windows das Eventlog durchsucht werden soll. |
| criticalpatterns | Ein regulärer Ausdruck oder ein Array regulärer Ausdrücke. Passt ein solcher Ausdruck zu einer Zeile in der Logdatei, dann wird dies als Critical Event betrachtet. Wenn dem Ausdruck ein “!” vorangestellt wurde, dann kehrt sich die Bedeutung um. Es wird dann ein Critical Event erzeugt, wenn keine Zeile im Logfile gefunden wurde, die zu diesem Pattern passt. |
| criticalexceptions | Ein oder mehrere reguläre Ausdrücke, welche im soeben erwähnten Fall den Event wieder in einen OK Event verwandeln. Dient z.B. dazu, um Sonderfälle abzufangen. |
| warningpatterns | Entspricht criticalpatterns, nur dass in diesem Fall ein Warning Event erzeugt wird. |
| warningexceptions | s.o. |
| okpatterns | Ein regulärer Ausdruck oder ein Array regulärer Ausdrücke. Wird so ein Ausdruck gefunden, dann werden die Fehlerzähler auf Null gesetzt und alle bisher gefundenen critical/warningpatterns verworfen. |
| script | Bei einem Treffer kann ein Script ausgeführt werden, wenn dies gewünscht ist. Es muss sich in einem der Verzeichnisse befinden, welche mit $scriptpath angegeben wurden. Die relevante Information wird per Environmentvariablen an das Script übergeben. |
| scriptparams | Optional können an ein Script auch Kommandozeilenparameter übergeben werden. Diese können auch Macros enthalten. Wenn $script eine Codereferenz ist, dann muss $scriptparams ein Zeiger auf ein Array sein. |
| scriptstdin | Wenn das Script Eingabe von Stdin erwartet, so kann man hier den entsprechenden String beschreiben. Dieser kann wiederum Macros enthalten. |
| scriptdelay | Nachdem das Script beendet ist, wird eine Pause von <delay> Sekunden eingelegt, bevor check_logfiles seine Arbeit wieder aufnimmt. |
| options | Hier kann ein String mit kommaseparierten Optionen angegeben werden. Jede Option kann mit “no” beginnen und somit das Abschalten der entsprechenden Funktionalität bewirken. Die einzelnen Optionen werden in der nächsten Tabelle beschrieben: |
| template | Anstelle eines Tags kann auch ein Template angegeben werden. Wenn check_logfiles mit der –tag Option aufgerufen wird, dann wird der entsprechende Search ausgeführt, als sei er mit einem Tagnamen definiert worden. (Siehe Beispiele) |
Optionen
| [no]script | Steuert, ob der script-Befehl ausgeführt wird. | default: aus |
| [no]smartscript | Steuert, ob Exitcode und Ausgabe des Scripts in die Trefferliste einfliessen sollen. | default: aus |
| [no]supersmartscript | Steuert, ob Exitcode und Ausgabe des Scripts den vorausgegangenen Treffer ersetzen sollen. | default: aus |
| [no]protocol | Steuert, ob die Treffer in einer eigenen Datei zur späteren Auswertung gespeichert werden. | default: ein |
| [no]count | Steuert, ob Treffer gezählt werden und in den Exitcode einfließen. Wenn nicht, kann check_logfiles auch nur zum Ausführen von Scripts benutzt werden. | default: ein |
| [no]syslogserver | Wird gesetzt, wenn in das Logfile auch Meldungen anderer Server einfließen. Mit syslogserver werden nur solche Zeilen betrachtet, die mit einem der Hostnamen des lokalen Hosts beginnen. | default: aus |
| [no]syslogclient=string | Dient der Vorfilterung. Es werden nur Zeilen untersucht, in denen der String vorkommt. | default: aus |
| [no]perfdata | Steuert, ob die Resultate als Performance Data angezeigt werden sollen. | default: ein |
| [no]logfilenocry | Steuert, was passiert, wenn das Logfile nicht existiert. Die Option nologfilenocry toleriert diesen Fall. Defaultmässig wäre das ein Grund für einen UNKNOWN Error. | default: ein |
| logfilemissing | Wird verwendet, um o.g. UNKNOWN in einen anderen Status zu ändern. Mit logfilemissing=critical lässt sich dann z.b. eine check_file_existence-Funktionalität abbilden. | default: unknown |
| [no]case | Steuert, ob in den Suchmustern zwischen Groß- und Kleinschreibung unterschieden wird | default: ein |
| [no]sticky[=Sekunden] | Steuert, ob ein Fehler von Lauf zu Lauf weitergereicht wird. Der Exitcode von check_logfiles ist in so einem Fall auch dann != 0, wenn keine neuen Fehlermeldungen mehr im Logfile aufgetaucht sind. Der Fehlerzustand wird entweder durch ein okpattern oder nach Ablauf der angegebenen Dauer beendet. Wer nicht auf Anhieb den Sinn diese Option versteht, sollte die Finger davon lassen. | default: aus |
| [no]savethresholdcount | Steuert, ob die Trefferzähler zwischen den Läufen erhalten bleiben. Falls ja, werden Treffer solange aufaddiert, bis ein Schwellwert (criticalthreshold) erreicht wird. Andernfalls wird bei jedem Lauf von Null an hochgezählt. | default: ein |
| [no]encoding=string | Ist ein Hinweis darauf, daß das Logfile in Unicode codiert ist. (z.b. ucs-2) | default: aus |
| [no]maxlength=zahl | Sorgt dafür, daß immens lange Zeilen ab der <zahl>-ten Stelle abgeschnitten werden | default: aus |
| [no]winwarncrit | Kann anstelle von Patterns verwendet werden, um alle Events des Typs WARNING/ERROR aus dem Windows-Eventlog zu holen | default: aus |
| [no]criticalthreshold=zahl | Eine Zahl N, die bedeutet, dass jeweils erst jeder N-te Treffer als Fehler gezählt wird. | default: aus |
| [no]warningthreshold=zahl | Eine Zahl N, die bedeutet, dass jeweils erst jeder N-te Treffer als Warning gezählt wird. | default: aus |
| [no]allyoucaneat | Beim initialen Lauf (also wenn noch kein Seekfile existiert) wird die Logdatei komplett durchsucht. | default: aus |
| [no]eventlogformat | Beim Durchsuchen des Windows Eventlog wird normalerweise nur das Feld Message ausgewertet und ausgegeben. Mit dieser Option kann der Eventtext um zusätzliche Informationen (Source, EventID,..) angereichert werden. (Details findet man weiter unten) | default: aus |
| [no]randominode | Ignorieren der Inode-Nummer bei der Rotationserkennung. Diese Option bitte nur für Spezialfälle verwenden, in denen sich die Inode der Logdatei permanent ändert. (Wenn z.B. bei jedem Anhängen einer neuen Meldung die Datei komplett neu erzeugt wird) | default: aus |
| [no]randomdevno | Ignorieren der Device-Nummer bei der Rotationserkennung. Diese Option bitte nur für Spezialfälle verwenden, in denen sich die Nummer des Devices, auf welchem die Logdatei liegt, permanent ändert. Sowas kann z.b. vorkommen bei einer VM mit KVM-Disk. | default: aus |
| [no]preferredlevel=level | Falls warningpatterns und criticalpatterns so gewählt wurden, daß bei einer bestimmten Zeile beide zum Tragen kommen (also “1 error, 1 warning” ausgegeben wird), so so sorgt diese Option dafür, daß nur der bevorzugte Level gezählt wird. (Bei preferredlevel=critical wäre die Ausgabe dann “1 error”) | default: aus |
| [no]savestate | Diese Option bewirkt, dass auch für Searches vom Typ virtual ein Seekfile geschrieben wird | default: aus |
| [no]capturegroups | Wenn ein Pattern runde Klammern zwecks Gruppierung enthält, so werden die Variablen $1, $2, … in den Macros CL_CAPTURE_GROUP1, CL_CAPTURE_GROUP2, … gespeichert. Die Gesamtzahl der Gruppen (höchste laufende Nummer von CL_CAPTURE_GROUPx) steht in CL_CAPTURE_GROUPS. | |
| Man verwendet diese Macros am Besten in ihrer Form als Environvariablen in Handler-Scripts, um z.B. eine Trefferzeile umzuschreiben bzw. relevante Informationen aus ihr zu extrahieren. | default: aus | |
| maxage=zeitdauer | Damit kann eine zusätzliche Prüfung auf Aktualität erfolgen. Zeitdauer ist: <zahl>[s|m|h]. Wenn die Logdatei seit der Zeitdauer (z.b. 2h) nicht mehr geändert wurde (mtime), dann wird das als CRITICAL gezählt. | default: aus |
Vordefinierte Macros
| $CL_USERNAME | Der Name des Users, der check_logfiles ausführt |
| $CL_HOSTNAME$ | Der Hostname ohne Domain |
| $CL_DOMAIN$ | Die DNS-Domain |
| $CL_FQDN$ | Beides zusammen |
| $CL_IPADDRESS$ | Die IP-Adresse |
| $CL_DATE_YYYY$ | Das aktuelle Jahr |
| $CL_DATE_MM$ | Der aktuelle Monat (1..12) |
| $CL_DATE_DD$ | Der aktuelle Tag des Monats |
| $CL_DATE_HH$ | Die aktuelle Stunde (0..23) |
| $CL_DATE_MI$ | Die aktuelle Minute |
| $CL_DATE_SS$ | Die aktuelle Sekunde |
| $CL_DATE_CW$ | Die aktuelle Kalenderwoche (ISO 8601:1988) |
| $CL_SERVICEDESC$ | Der Dateiname der Konfigurationsdatei ohne Extension |
| $CL_NSCA_SERVICEDESC$ | dto. |
| $CL_NSCA_HOST_ADDRESS$ | Die lokale Adresse 127.0.0.1 |
| $CL_NSCA_PORT$ | 5667 |
| $CL_NSCA_TO_SEC$ | 10 |
| $CL_NSCA_CONFIG_FILE$ | send_nsca.cfg |
| Folgende Macros ändern ihren Wert zur Laufzeit | |
| $CL_TAG$ | Der Bezeichner des aktuellen Laufs ($CL_tag$ enthält den Tag in Kleinbuchstaben) |
| $CL_TEMPLATE$ | Der Name des verwendeten Templates (falls in der search-Definition verwendet) |
| $CL_LOGFILE$ | Die Datei, die durchsucht werden soll |
| $CL_SERVICEOUTPUT$ | Die zuletzt gefundene Zeile im Logfile |
| $CL_SERVICESTATEID$ | Der Status als Zahl 0..3 |
| $CL_SERVICESTATE$ | Der Status als Wort (OK, WARNING, CRITICAL, UNKNOWN) |
| $CL_SERVICEPERFDATA$ | Die Performancedaten |
| $CL_PROTOCOLFILE$ | Die Datei in die alle Treffer geschrieben werden. |
Diese Macros stehen auch in Scripts, die aus check_logfiles heraus aufgerufen werden, als Environmentvariablen zur Verfügung. Dabei wird das “CL_” im Namen durch “CHECK_LOGFILES_” ersetzt. Auch auf selbstdefinierte Macros kann zugegriffen werden. Ihrem Namen wird ebenfalls “CHECK_LOGFILES_” vorangestellt.
nagios:~> cat check_logfiles.cfg
$scriptpath = '/usr/bin/my_application/bin:/usr/local/nagios/contrib';
$MACROS = {
MY_FUNNY_MACRO => 'hihihihohoho',
MY_VOLUME => 'loud'
};
@searches = (
{
tag => 'fun',
logfile => '/var/adm/messages',
criticalpatterns => 'a funny pattern',
script => 'laugh.sh',
scriptparams => '$MY_VOLUME$',
options => 'noprotocol,script,perfdata'
},
);
nagios:~> cat /usr/bin/my_application/bin/laugh.sh
#! /bin/sh
if [ -n "$1" ]; then
VOLUME=$1
fi
printf "It is %d:%d and my status is %s\n" \
$CHECK_LOGFILES_DATE_HH \
$CHECK_LOGFILES_DATE_MI \
$CHECK_LOGFILES_SERVICESTATE
printf "I found something funny: %s\n" "$CHECK_LOGFILES_SERVICEOUTPUT"
if [ "$VOLUME" == "Xloud" ]; then
echo "$CHECK_LOGFILES_MY_FUNNY_MACRO" | tr 'a-z' 'A-Z'
else
echo "$CHECK_LOGFILES_MY_FUNNY_MACRO"
fi
printf "Thank you, %s. You made me laugh.\n" "$CHECK_LOGFILES_USERNAME"Die Anzahl der untersuchten Zeilen sowie die Anzahl der gefundenen Muster (Critical, Warning, Unknown) werden als Performancedaten an die Ausgabe des Plugins angehängt. Mit der Option “noperfdata” lässt sich dies abschalten.
nagios$ check_logfiles --logfile /var/adm/messages \
--criticalpattern 'Failed password' --tag ssh
CRITICAL - (4 errors) - May 9 11:33:12 localhost sshd[29742] Failed password for invalid user8 ... |ssh_lines27 ssh_warnings=0 ssh_criticals=4 ssh_unknowns=0
nagios$ check_logfiles --logfile /var/adm/messages \
--criticalpattern 'Failed password' --tag ssh --noperfdata
CRITICAL - (2 errors) - May 9 11:58:48 localhost sshd[29813] Failed password for invalid user8 ...Es besteht die Möglichkeit, zur Laufzeit von check_logfiles externe Scripts ausführen zu lassen. Das kann zu Beginn ($prescript), am Ende ($postscript) und jedesmal, wenn ein Pattern gefunden wurde (script) der Fall sein. Siehe obiges Beispiel.
Mit der Option “smartscript” werden Ausgabe und Exit Code (0-3) des Scripts wie ein Treffer in einem Logfile behandelt und fliessen in das Endergebnis ein. Die Option “supersmartscript” sorgt dafür, daß Ausgabe und Exitcode des Scripts den auslösenden Treffers ersetzen.
Pre- und Postscript können als supersmart scripts direkten Einfluss auf den Ablauf von check_logfiles nehmen. Die Option “supersmartprescript” sorgt dafür, daß check_logfiles sofort abgebrochen wird, wenn das Prescript einen Exitcode größer Null liefert. Ausgabe und Exitcode von check_logfiles entsprechen dann denen des Prescripts. Mit der Option “supersmartpostscript” kann man den Exitcode und die Ausgabe von check_logfiles durch das Postscript bestimmen lassen. Dadurch ist z.b. die Formulierung eines aussagekräftigeren Textes möglich.
Wenn nur ein Service definiert ist, der check_logfiles verwendet, dann kann der Pfad zur Konfigurationsdatei direkt angegeben werden.
define service {
service_description check_sanlogs
host_name oaschgeign.muc
check_command check_nrpe!check_logfiles
is_volatile 1
check_period 7x24
max_check_attempts 1
...
}
define command {
command_name check_nrpe
command_line $USER1$/check_nrpe -H $HOSTADDRESS$ -c $ARG1$
}
command[check_logfiles]=/opt/nagios/libexec/check_logfiles
--config logdefs.cfgBenutzen mehrere Services check_logfiles, dann sind auch mehrere Konfigurationsdateien nötig. Es wird empfohlen, diese nach den Servicenamen zu benennen. Im folgenden Beispiel würde es dann im Verzeichnis cfg.d die Dateien solaris_check_sanlogs und solaris_check_apachelogs geben.
define service {
service_description logfilescan
register 0
is_volatile 1
check_period 7x24
max_check_attempts 1
...
}
define service {
service_description solaris_check_sanlogs
host_name oaschgeign.muc
check_command
check_nrpe_arg!20!check_logfiles!cfg.d/$SERVICEDESC$
contact_group sanadmin
use logfilescan
}
define service {
service_description solaris_check_apachelogs
host_name oaschgeign.muc
check_command
check_nrpe_arg!20!check_logfiles!cfg.d/$SERVICEDESC$
contact_group webadmin
use logfilescan
}
define command {
command_name check_nrpe_arg
command_line $USER1$/check_nrpe
-H $HOSTADDRESS$ -t $ARG1$ -c $ARG2$ -a $ARG3$
}Der entsprechende Eintrag in der nrpe.cfg des Hosts sieht dann so aus:
[check_logfiles]=/opt/nagios/libexec/check_logfiles --config $ARG1$Falls Windows mit nsclient++ verwendet wird, sieht der Eintrag in der NSC.ini so aus:
check_logfiles=C:\Perl\bin\perl C:\libexec\check_logfiles --config $ARG1$Wenn man das Alertlog einer Oracle-Datenbank auslesen will, aber keinen Zugang zum Betriebssystem des DB-Servers (z.b. wenn es ein Windows-Server ist oder aus Sicherheitsgründen kein Login auf einem Unix-Server möglich ist) und somit keinen Zugang zur Alert-Datei hat, dann kann diese Datei auf eine Datenbanktabelle abgebildet werden. Der Inhalt der Datei ist dann auch über einen reinen Datenbankzugang mittels SQL-Befehlen sichtbar. Gibt man in einer check_logfiles-Konfiguration den Typ “oraclealertlog” an, dann wird dieser Weg benutzt, um die Alertdatei zu durchsuchen. Dazu sind einige zusätzliche Parameter nötig.
# extra parameters in the configuration file
@searches = ({
tag => 'oratest',
type => 'oraclealertlog',
oraclealertlog => {
connect => 'db0815', # connect identifier
username => 'nagios', # database user
password => 'hirnbrand', # database password
},
criticalpatterns => [
...Die Abbildung von externen Dateien auf Datenbanktabellen ist seit der Version 9 möglich. Mit diesem Script wird die Datenbank entsprechend vorbereitet:
create_alert_log_table.sql
Installation der Perl-Module DBI und DBD::Oracle (http://search.cpan.org/~pythian/DBD-Oracle-1.74/lib/DBD/Oracle.pm).
Das Eventlog von Windows-Systemen kann von check_logfiles auf die gleich Art wie herkömmliche Logdateien verarbeitet werden. Jeder Event steht für eine Zeile. Dabei werden auch hier nur die Events analysiert, die seit dem letzten Lauf von check_logfiles neu hinzugekommen sind.
In der einfachsten Form sieht eine entsprechende Konfiguration so aus:
@searches = ({
tag => 'evt_sys',
type => 'eventlog',
criticalpatterns => ['error', 'fatal', 'failed', ....
# logfile anzugeben ist hier nicht nötig, da sinnlos.Soll die Bewertung der Events nicht anhand von Patterns erfolgen, sondern durch die von Windows vorgegebenen Stati WARNING und ERROR, so benutzt man die Option winwarncrit.
@searches = ({
tag => 'evt_sys',
type => 'eventlog',
options => 'winwarncrit',Beim Typ eventlog ist es auch möglich, nur ganz bestimmte Events auszulesen und der Analyse zuzuführen. Dazu gibt es include- und exclude-Filter.
@searches = ({
tag => 'winupdate',
type => 'eventlog',
eventlog => {
eventlog => 'system',
include => {
source => 'Windows Update Agent',
eventtype => 'error,warning',
},
exclude => {
eventid => '15,16',
},
},
criticalpatterns => '.*',Diese Einstellungen sorgen dafür, dass aus dem Eventlog nur solche Events ausgelesen werden, die folgende Bedingungen erfüllen:
* Das System-Eventlog wird geöffnet
* Nur die Events werden gelesen, die von der Source “Windows Update Agent” stammen.
* Nur Errors und Warnings werden gelesen.
* Events mit den IDs 15 und 16 werden verworfen. ( Es konnte keine Verbindung mit dem Dienst “Automatische Updates” hergestellt werden )
Es ist zu beachten, dass die einzelnen include-Bedingungen UND-verknüpft und die exclude-Bedingungen ODER-verknüpft sind. Die durch Komma getrennten Listen sind immer ODER-verknüpft.
filter = ((source == "Windows Update Agent") AND ((eventtype == "error") OR (eventtype == "warning"))) AND NOT ((eventid == 15) OR (eventid == 16))Dieses Verhalten kann man ändern, indem man die Bedingung “operation” mit einem der Argumente “and” oder “or” angibt.
@searches = ({
tag => 'winupdate',
type => 'eventlog',
eventlog => {
eventlog => 'system',
include => {
source => 'Windows Update Agent',
eventtype => 'error,warning',
operation => 'or',
},
exclude => {
eventid => '15,16',
},
},
criticalpatterns => '.*',Dieser Filter besagt: “Windows Update Agent” OR (“error” OR “warning”)
type => 'eventlog',
eventlog => {
eventlog => 'system', # system (default), application, security
include => {
source => 'Windows Update Agent', # die Herkunft (Source) des Events
eventtype => 'error,warning', # error, warning, info, success, auditsuccess, auditfailure
operation => 'or' # die logische Verknüpfung. Default ist "and"
},
exclude => {
eventid => '15,16', # die ID des Events
},
},Auch im Commandline-Modus kann man Filter angeben.
check_logfiles --type "eventlog:eventlog=application,include,source=Windows Update Agent,eventtype=error,eventtype=warning,exclude,eventid=15,eventid=16"Mit einer weiteren Option ist es möglich, den Eventtext umzuformulieren. Normalerweise sieht check_logfiles beim Pattern Matching nur das Feld Message eines Events. Dieses erscheint auch in der Ausgabe des Plugins. Die Option “eventlogformat” dient dazu, auch die Felder EventType, Source, Category, Timewritten und TimeGenerated in der Ausgabe erscheinen zu lassen.
EventType: ERROR
EventID: 16
Source: W32Time
Category: None
Timewritten: 1259431241
TimeGenerated: 1259431241
Message: Der NtpClient verfügt über keine Quelle mit genauer Zeit.options => 'eventlogformat="%w src:%s id:%i %m"',Mit diesen Einstellungen wird beim Auslesen des Events dessen Message so umgeschrieben, dass sie lautet:
2009-11-28T19:04:16 src:W32Time id:16 Der NtpClient verfügt über keine Quelle mit genauer Zeit.Der Formatstring kennt folgende Platzhalter:
%t EventType
%i EventID
%s Source
%c Category
%w Timewritten
%g TimeGenerated
%m MessageMit %<zahl>m kann man die Message auf zahl Zeichen verkürzen.
Windows-Versionen vor Vista benutzten das Eventlog-Format EVT. Seit Windows Vista bzw. Windows Server 2008 gibt es eine neues Format (und ein neues API), welches EVTX oder Crimson genannt wird. Neu ist auch, daß es nicht mehr nur die bekannten Windows Logs wie “application”, “system” und “security” gibt, sondern eine Vielzahl von Application and Service Logs.
Beispiele sind Microsoft-Windows-PowerShell/Operational, Microsoft/Exchange/HighAvailability/Operational uvm.
Seit der Version 3.7 kann check_logfiles auch diese sogenannten Channels durchsuchen.
@searches = ({
tag => "msps",
type => "wevtutil",
criticalpatterns => ["Microsoft", "PowerShell.*(ready|bereit)" ],
warningpatterns => ["PowerShell.*(started|gestartet)" ],
wevtutil => {
eventlog => "Microsoft-Windows-PowerShell/Operational",
}
});Hier gibt es Beispiele für die verschiedensten Anwendungsfälle.
Hier steht, wie man eine check_logfiles.exe-Datei erzeugt. Benutzt man diese, so ist keine Perl-Installation unter Windows mehr nötig.
Check_logfiles wird unter der GNU General Public License zur Verfügung gestellt.
Gerhard Laußer (gerhard.lausser@consol.de) beantwortet gerne Fragen zu diesem Plugin.